ทักษะ (ระบุได้หลายทักษะ)
รู้จักกับโครงสร้างข้อมูล แบบ Dimensionl Model
Microsoft ได้ออกแบบผลิตภัณฑ์ Microsoft SQL Server Integration Service ให้สามารถสกัดข้อมูลจากหลายแหล่งหลายโครงสร้าง (schema)
แล้วมีเครื่องไม้เครื่องมือในการแปลงข้อมูลเหล่านั้นไปสู่โครงสร้าง (schema)แบบ Dimensional Model ของ Ralph Kimball
ผู้อ่านสามารถติดตามหนังสือในเครือ Kimball Group ได้จาก http://www.kimballgroup.com
แล้วมีเครื่องไม้เครื่องมือในการแปลงข้อมูลเหล่านั้นไปสู่โครงสร้าง (schema)แบบ Dimensional Model ของ Ralph Kimball
ผู้อ่านสามารถติดตามหนังสือในเครือ Kimball Group ได้จาก http://www.kimballgroup.com
การรวบรวมข้อมูลไปไว้ในโครงสร้าง (schema) แบบ Dimensional Model นั้น
ทำให้ข้อมูลพร้อมที่จะถูกนำไปวิเคราะห์หรือออกรายงานแล้วลดทอนประสิทธิภาพของ RDBMS ลงน้อยกว่า การสืบค้นจาก Relational Model แบบเดิม ๆ
(แต่ก็ยังไม่ถึงที่สุด หากยังไม่นำไปสร้าง Data Model เก็บไว้ล่วงหน้าด้วย Microsoft SQL Server Analysis Service)
ทำให้ข้อมูลพร้อมที่จะถูกนำไปวิเคราะห์หรือออกรายงานแล้วลดทอนประสิทธิภาพของ RDBMS ลงน้อยกว่า การสืบค้นจาก Relational Model แบบเดิม ๆ
(แต่ก็ยังไม่ถึงที่สุด หากยังไม่นำไปสร้าง Data Model เก็บไว้ล่วงหน้าด้วย Microsoft SQL Server Analysis Service)
สำหรับบทความนี้ ผู้เขียนจะขยายความให้ท่าน รู้จักกับโครงสร้างข้อมูล แบบ Dimensionl Model กันครับ
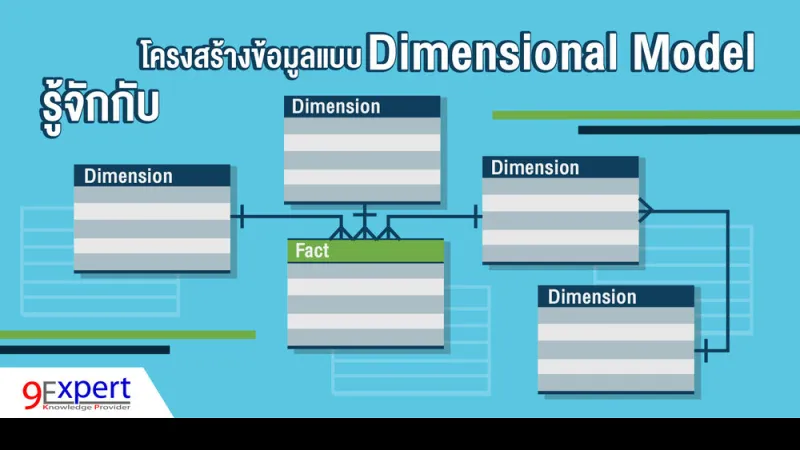
โครงสร้าง (schema) แบบ Star Schema ใน Dimensional Model ถูกนำมาใช้อย่างกว้างขวางเพราะเป็นรูปแบบที่ง่าย
คือ มี Fact Table อยู่ตรงกลาง รายล้อมด้วยบรรดา Dimension Tables
โดยข้อมูลใน Fact Table จะเป็นบรรดาค่าตัวเลขทางธุรกิจ (measures, metrics)
ส่วนข้อมูลใน Dimension Tables จะเป็นคุณลักษณะ (attributes) ที่ใช้บรรยายข้อมูลใน Fact Table
โครงสร้าง (schema) แบบ Star Schema ใน Dimensional Model ถูกนำมาใช้อย่างกว้างขวางเพราะเป็นรูปแบบที่ง่าย
คือ มี Fact Table อยู่ตรงกลาง รายล้อมด้วยบรรดา Dimension Tables
โดยข้อมูลใน Fact Table จะเป็นบรรดาค่าตัวเลขทางธุรกิจ (measures, metrics)
ส่วนข้อมูลใน Dimension Tables จะเป็นคุณลักษณะ (attributes) ที่ใช้บรรยายข้อมูลใน Fact Table
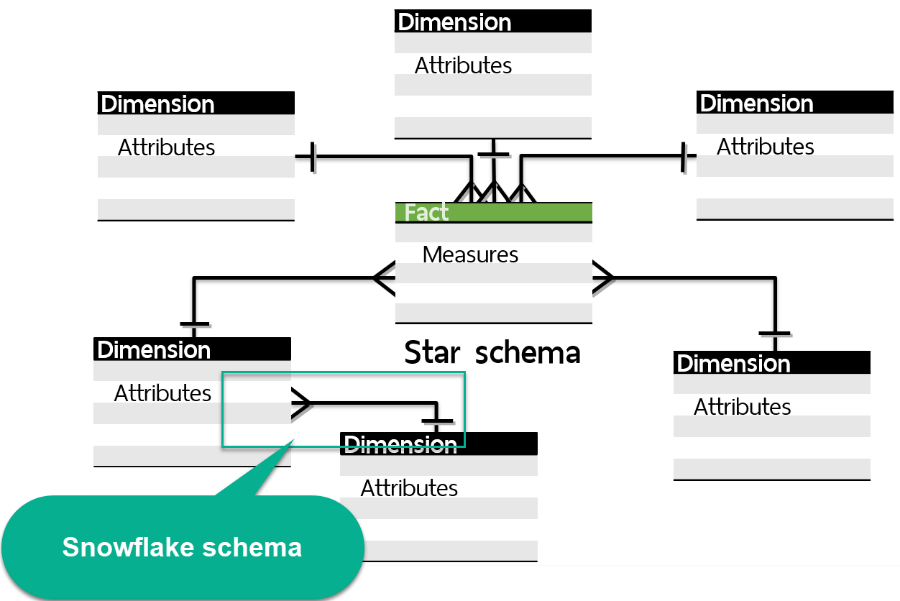
และหากมี Dimension Table ทำหน้าที่อธิบาย Dimension Table อีกชั้นหนึ่ง ก็จะกลายเป็น Snowflake Schema
ซึ่งโครงสร้างแบบนี้เกิดขึ้นเพราะต้องการ Normalized ให้กับ Dimension Table นั้น ๆ แต่ก็จะไปเพิ่มความซับซ้อนขึ้นใน Dimensional Model
ซึ่งโครงสร้างแบบนี้เกิดขึ้นเพราะต้องการ Normalized ให้กับ Dimension Table นั้น ๆ แต่ก็จะไปเพิ่มความซับซ้อนขึ้นใน Dimensional Model
ผู้เขียนเห็นความต่างของ Relational Model ที่มุ่งเน้นไปที่การ Normalized ให้กับตารางทุกตาราง
แต่สำหรับ Dimensional Model มีส่วนผสมระหว่าง De-Normalized กับ Normalized ปนอยู่ด้วยกัน
หากใครไปค้นคว้าผ่านผู้รู้ต่าง ๆ อาจได้ความเห็นเกี่ยวกับ Fact Table ไปสองทาง
ทางหนึ่งบอกว่าเป็น De-Normalized แต่ตำราส่วนใหญ่บอกว่าเป็น Completely Normalized Table
สำหรับ Dimension Tables ค่อยเป็นไปทางเดียวกัน คือเป็น De-Normalized Table สำหรับบน Star Schema
แต่หากพยายามทำให้เป็น Normalized Table ก็จะกลายเป็น Snowflake Schema
แต่สำหรับ Dimensional Model มีส่วนผสมระหว่าง De-Normalized กับ Normalized ปนอยู่ด้วยกัน
หากใครไปค้นคว้าผ่านผู้รู้ต่าง ๆ อาจได้ความเห็นเกี่ยวกับ Fact Table ไปสองทาง
ทางหนึ่งบอกว่าเป็น De-Normalized แต่ตำราส่วนใหญ่บอกว่าเป็น Completely Normalized Table
สำหรับ Dimension Tables ค่อยเป็นไปทางเดียวกัน คือเป็น De-Normalized Table สำหรับบน Star Schema
แต่หากพยายามทำให้เป็น Normalized Table ก็จะกลายเป็น Snowflake Schema
According to Kimball:
Dimensional models combine normalized and denormalized table structures. The dimension tables of descriptive information are highly denormalized with detailed and hierarchical roll-up attributes in the same table. Meanwhile, the fact tables with performance metrics are typically normalized.
รู้จักกับ Fact Table พอสังเขป
Fact Table จะจัดเก็บข้อมูลค่าตัวเลขทางธุรกิจ (measures, metrics)
ประกอบด้วยสองส่วนคือ
ประกอบด้วยสองส่วนคือ
- บรรดา Foreign Keys ที่อ้างอิงไปยังบรรดา Dimension Tables ที่เกี่ยวข้อง
- และ Measurements หรือ Metrics ต่าง ๆ
USE AdventureWorksDW;
SELECT
ProductKey
, OrderDateKey
, DueDateKey
, ShipDateKey
, ResellerKey
, EmployeeKey
, PromotionKey
, CurrencyKey
, SalesTerritoryKey
, SalesOrderNumber
, OrderQuantity
, ProductStandardCost
, TotalProductCost
, SalesAmount
, DiscountAmount
FROM FactResellerSales;
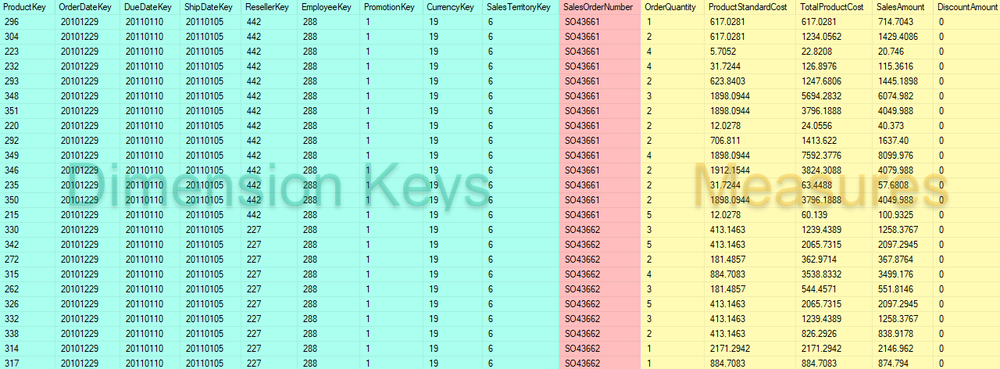
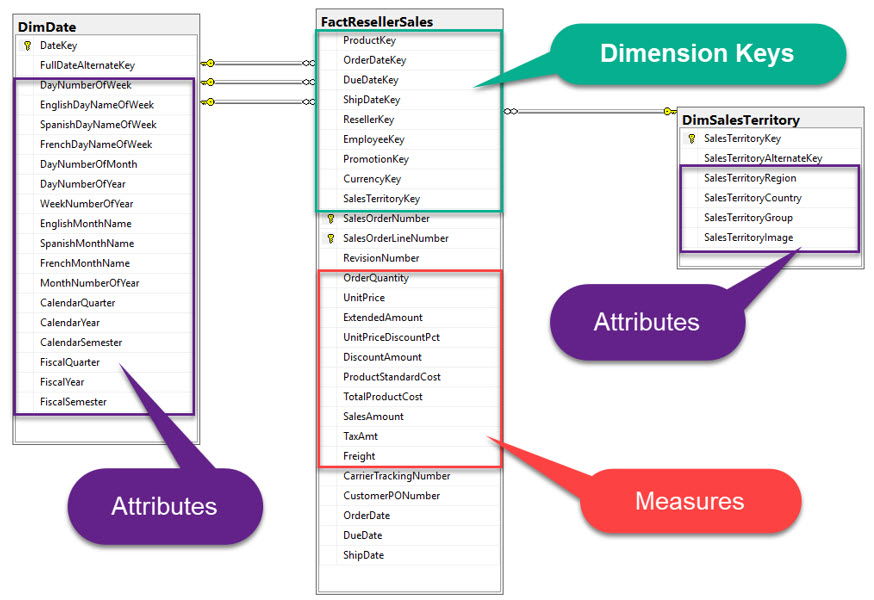
จากผลลัพธ์จะเห็นว่าใน Fact Table อ้างอิงไปยังบรรดา Dimension Tables ที่เกี่ยวข้องผ่าน Surrogate Key ที่เป็น integer (สีเขียว)
ในบางครั้งอาจมีบางคอลัมน์ที่ทำหน้าที่เป็น Dimension Key แต่ไม่ต้องมี Dimension Table ให้อ้างอิง เช่น คอลัมน์ SalesOrderNumber (สีแดง)
และส่วนที่เหลือ (สีเหลือง) เป็นคอลัมน์ของบรรดา measures ที่เราจะนำหาผลรวมตาม Dimensions ที่เกี่ยวข้องต่อไป
และส่วนที่เหลือ (สีเหลือง) เป็นคอลัมน์ของบรรดา measures ที่เราจะนำหาผลรวมตาม Dimensions ที่เกี่ยวข้องต่อไป
Fact Table จะถูกออกแบบให้จัดเก็บข้อมูลให้มีระดับความละเอียด (gain หรือ granularity) เดียวกันทั้งตาราง
โดยตาราง FactResellerSales เป็นตารางรายการสั่งซื้อผ่านตัวแทนขาย (Reseller Sales) ที่มี gain ละเอียดระดับ 1 วัน
สังเกตได้จากบรรดา DateKey
โดยตาราง FactResellerSales เป็นตารางรายการสั่งซื้อผ่านตัวแทนขาย (Reseller Sales) ที่มี gain ละเอียดระดับ 1 วัน
สังเกตได้จากบรรดา DateKey
รู้จักกับ Dimension Table พอสังเขป
ข้อมูลใน Dimension Tables จะเป็นคุณลักษณะ (attributes) ที่ใช้บรรยายข้อมูลใน Fact Table
USE AdventureWorksDW;
USE AdventureWorksDW;
SELECT
DateKey
, FullDateAlternateKey
, DayNumberOfWeek
, EnglishDayNameOfWeek
, DayNumberOfMonth
, WeekNumberOfYear
, EnglishMonthName
, MonthNumberOfYear
, CalendarQuarter
, CalendarSemester
, CalendarYear
FROM DimDate;
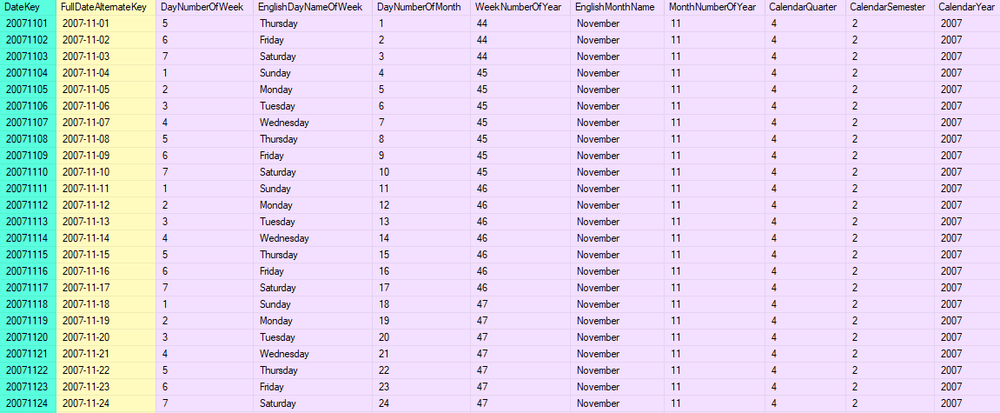
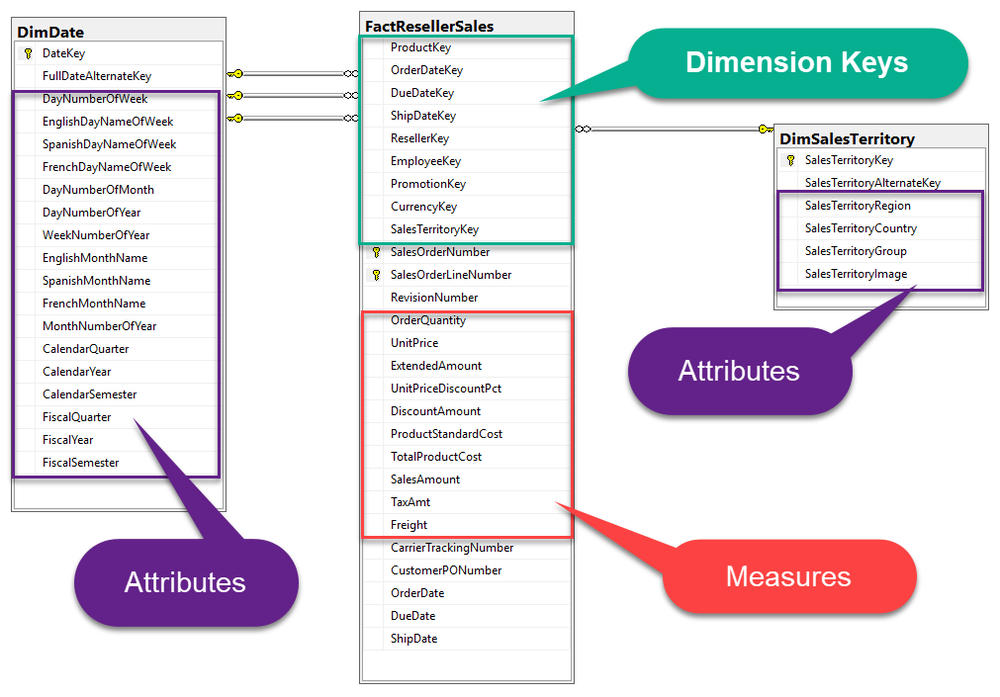
จากผลลัพธ์จะเห็นว่าใน Dimension Table ประกอบด้วย
- Surrogate Key (สีเขียว) เป็นเลข Integer ที่มักรันเพิ่มทางบวกไปเรื่อย ๆ
- และ Business Key หรือ Alternate Key (สีเหลือง) ใช้อ้างอิงกับ Key เดิมในระบบต้นทาง
ในกรณีนี้ระบบต้นทางคือฐานข้อมูล Adventureworks เรามักสกัดข้อมูลต้นทาง
และทำการแปลงให้มีโครงสร้างเหมาะสมกับระบบปลายทางในที่นี้คือฐานข้อมูล AdventureworksDW ผ่าน Microsoft SQL Server Integration Service)
- และคอลัมน์ที่เหลือ (สีม่วง) ทำหน้าที่เป็น Attributes ซึ่งบางคอลัมน์ก็มีคุณสมบัติในการเป็น Hierarchy อีกด้วย
การออกแบบ Dimension Table บางครั้งมีความต้องการเก็บ History ของข้อมูลด้วย
เราสามารถใช้หลักการของ Slowly Changing Dimension (SCD) ซึ่งมีทั้งหมด 7 ชนิด แต่บางชนิดก็ไม่เหมาะสมที่จะใช้งานจริง
เราสามารถใช้หลักการของ Slowly Changing Dimension (SCD) ซึ่งมีทั้งหมด 7 ชนิด แต่บางชนิดก็ไม่เหมาะสมที่จะใช้งานจริง
ผู้อ่านสามารถดูได้จากลิงก์นี้ https://en.wikipedia.org/wiki/Slowly_changing_dimension
ผู้เขียนได้ทดลองสืบค้นข้อมูลจากตาราง DimEmployee ซึ่งเป็น SCD Type 2 ดังสคริปต์ต่อไปนี้
USE AdventureWorksDW;
SELECT
EmployeeKey
, EmployeeNationalIDAlternateKey
, FirstName
, LastName
, Title
, HireDate
, BirthDate
, Phone
, MaritalStatus
, Gender
, DepartmentName
, StartDate
, EndDate
, Status
FROM AdventureWorksDW.dbo.DimEmployee
WHERE EmployeeNationalIDAlternateKey=895209680;

จากผลลัพธ์จะเห็นว่าเป็นข้อมูลของ Employee คนเดียวกันทั้งหมด เพราะมี EmployeeNationlIDAlternateKey เดียวกัน
และเป็นการใช้คอลัมน์ StartDate, EndDate และ Status เป็นตัวบอกว่าเป็นข้อมูลปัจจุบันหรือไม่
หาก EndDate มีการบันทึก แสดงว่าเป็นข้อมูลเก่า
แต่หากยังไม่บันทึกและคอลัมน์ Status เป็น “Current” แสดงว่าเป็นข้อมูลปัจจุบัน
โดย Employee รายนี้เปลี่ยนข้อมูลมาแล้ว 4 ครั้ง
และเป็นการใช้คอลัมน์ StartDate, EndDate และ Status เป็นตัวบอกว่าเป็นข้อมูลปัจจุบันหรือไม่
หาก EndDate มีการบันทึก แสดงว่าเป็นข้อมูลเก่า
แต่หากยังไม่บันทึกและคอลัมน์ Status เป็น “Current” แสดงว่าเป็นข้อมูลปัจจุบัน
โดย Employee รายนี้เปลี่ยนข้อมูลมาแล้ว 4 ครั้ง
- ครั้งที่ 1 เปลี่ยนเบอร์โทรศัพท์จาก 210-6920-8398 เป็น 210-555-0193
- ครั้งที่ 2 เปลี่ยนสถานะแต่งงานจาก โสด เป็น แต่งงานแล้ว
- ครั้งที่ 3 เปลี่ยนตำแหน่งงานจาก พนักงานจัดซื้อ ไปเป็น ผู้จัดการฝ่ายจัดซื้อ
- ครั้งที่ 4 เปลี่ยนนามสกุลจาก Wood ไปเป็น Trump
จะเห็นว่าทุกครั้งที่เปลี่ยนมีการบันทึกลงในแถวข้อมูลใหม่ และมี Surrogate Key เลขใหม่
ประโยชน์ของ Dimensional Model
เนื่องจาก Dimensional Model เป็นส่วนผสมระหว่าง De-Normalized กับ Normalized
เนื่องจาก Dimensional Model เป็นส่วนผสมระหว่าง De-Normalized กับ Normalized
ทำให้กฎเกณฑ์การ Normalization ได้รับการผ่อนปนลงไปมาก เป็นผลให้
- ง่ายต่อการ Queries เพราะไม่ต้องดำเนินการ join ที่ซับซ้อน
- เพิ่มประสิทธิภาพในการ Queries
- นำไปหาผลรวมได้เร็วขึ้น เพราะลดขั้นตอนการ join ที่ซับซ้อนลงไปได้มาก
- ส่งต่อให้กับ Multidimensional Data Model หรือ Tabular Data Model
จะเห็นว่า Microsoft SQL Server Integration Service ได้ทำหน้าที่รวบรวมข้อมูลจากหลายแหล่งข้อมูลไปรวมกันไว้ใน Data Warehouse
แล้วเราจะได้ Data Warehouse แบบ Dimensional Model ซึ่งเป็นโครงสร้างข้อมูลที่สามารถส่งต่อให้กับ Microsoft SQL Server Analysis Service เพื่อใช้สร้าง Data Model ได้
ทั้งนี้เป็นการรวบรวมข้อมูลเอาไว้ให้ Queries ได้ง่ายขึ้น แต่ยังไม่ได้หาผลรวมจาก measures ที่เตรียมไว้เลย
หากจะออกรายงานจาก Dimensional Model ก็สามารถทำได้ แต่ต้องทำการ Group by เพื่อหาผลรวมนำไปออกรายงานเป็นครั้ง ๆ
ซึ่งหากจำนวนครั้ง และความหลากหลายของรายงานมีไม่มาก ก็ยังไม่ส่งผลประทบต่อประสิทธิภาพของ Database Engine เท่าไหร่
แต่ถ้าจำนวนครั้ง และความหลากหลายของรายงานมีมาก เราควรพิจารณาใช้ Data Model ระดับ Enterprise มาทดแทนดีกว่า
สำหรับการสร้าง Data Model นั้นสามารถอ่านต่อได้ที่ 2 บทความข้างล่างนี้ครับ
- การสร้าง Data Model ด้วย Microsoft SQL Server Analysis Service และการเรียกใช้
- การสร้าง Data Model บน Power BI เองไม่ผ่าน Microsoft SQL Server Analysis Service
บทความนี้เป็นส่วนหนึ่งของหลักสูตร Microsoft SQL Server 2017 Business Intelligence