มารู้จักกับ SQL Server Indexes และ Database Engine Tuning Advisor
มีอยู่สองเรื่องที่ผู้เขียนได้รับการร้องขอให้เขียนก็คือ Indexes และ Database Engine Tuning Advisor ซึ่งผู้เขียนเห็นว่ามีความสัมพันธ์กันอยู่เลยนำมาเขียนเป็นบทความเดียวกัน
หากพูดถึง Indexes ใน Microsoft SQL Server 2016 นั้นมีเยอะมากดังนี้
- Index ปกติที่ใช้กันทั่วไป
- Clustered Index
- Non-Clustered Index
- Index ลำหรับงาน Data Warehouse และ Real-Time Analytics
- Columnstore Index
- Index สำหรับเอกสาร XML
- Index สำหรับ Spatial Data (Geography
บทความนี้ผู้เขียนจะกล่าวถึงเฉพาะ Indexes ปกติที่เรา ๆ ท่าน ๆ ใช้กันอยู่ และก่อนที่จะทำความรู้จัก Indexes ผู้เขียนมักจะต้องพูดถึง Heap ก่อน
โดยความหมายของ Heap หากค้นหาผ่าน Google โดยใช้ Keyword ว่า “heap table in sql server” จะแสดงกรอบผลลัพธ์ดังนี้
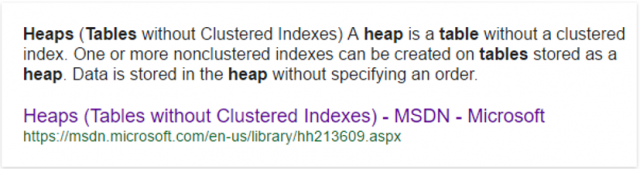
ซึ่งผู้เขียนมองว่าเป็นนิยามของ Heap (เฉพาะที่ใช้ใน Microsoft SQL Server อาจต่าง ๆ ไปจาก Heap Allocation ที่เคยเรียนกันใน Data Structure อยู่บ้าง)
ที่ให้ความกระจ่างที่สุดแล้ว ก็คือ “โครงสร้าง Table ที่ไม่ใช่ Clustered Index” นั่นเอง
โปรดสังเกตผู้เขียนใช้คำว่า โครงสร้าง Table เพราะข้อมูลของ Table จะถูกใส่ลงใน Pages ข้อมูล
ที่มีการจัดสรรแบบ Heap หรือ Clustered Index อย่างใดอย่างหนึ่งเท่านั้น
ผู้เขียนจะพิสูจน์ด้วยตัวอย่างง่ายๆ ดังนี้
USE TestDB;
GO
CREATE SCHEMA TEST;
GO
CREATE TABLE TEST.TestTable
(
Column1 varchar(10) NOT NULL
, Column2 varchar(10) NOT NULL
);
GO
DECLARE @objID int =OBJECT_ID('TEST.TestTable');
SELECT
CONVERT(varchar(20),OBJECT_NAME(@objID)) as ObjName
, type as IdxType
, CONVERT(varchar(20),type_desc) as IdxTypeName
FROM sys.indexes
WHERE object_id=@objID;
GO
จะเห็นว่าผู้เขียนสร้างตาราง TEST.TestTable ขึ้นมาใหม่ โดยตารางนั้นไม่มีการสร้าง Index แต่อย่างใด
และในส่วนของ Script ด้านล่างคือการค้นหา Indexes ที่มีการสร้างบนตาราง TEST.TestTable นั่นเอง
ผลลัพธ์ที่ได้คือ

จะเห็นว่าแม้ไม่มีการสร้าง Indexes บนตารางดังกล่าว แต่ก็มีการระบุ Index Type ไว้เป็น Heap
(Heap ไม่ใช่ Index แต่แสดงผลร่วมบนตารางที่เก็บ Metadata ของ Indexes ในกรณี Microsoft SQL Server ตั้งแต่เวอร์ชั่น 2008 คือ sys.indexes สามารถดูรายละเอียดเพิ่มเติมจาก MSDN)
ผู้เขียนจะแสดง Objects ภายใต้ตาราง TEST.TestTable เฉพาะส่วนของ Indexes ผ่าน SSMS ให้เห็นดังนี้
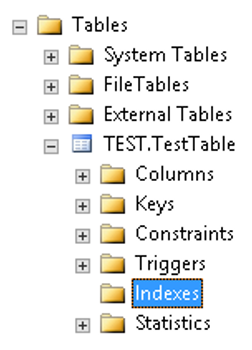
จะเห็นว่าภายใต้ Folder ชื่อว่า Indexes ไม่มี Indexes อะไรอยู่เลย
แล้ว Heap มาจากอะไรกันแน่ ผู้เขียนเลยลองพิสูจน์ให้เห็นเพิ่มเติมด้วยตัวอย่างดังต่อไปนี้
USE TestDB;
GO
CREATE TABLE TEST.TestTable_PKEY
(
Column1 varchar(10) NOT NULL PRIMARY KEY
, Column2 varchar(10) NOT NULL
);
GO
DECLARE @objID int =OBJECT_ID('TEST.TestTable_PKEY');
SELECT
CONVERT(varchar(20),OBJECT_NAME(@objID)) as ObjName
, type as IdxType
, CONVERT(varchar(20),type_desc) as IdxTypeName
FROM sys.indexes
WHERE object_id=@objID;
GOในส่วนของตัวอย่างใหม่นี้ผู้เขียนได้สร้างตาราง TEST.TestTable_PKEY
โดยกำหนดให้ Column1 บนตาราง เป็น Primary Key Constraint
ผลลัพธ์เมื่อผ่านการสืบค้น Metadata ของ Indexes บนตารางดังกล่าวคือ
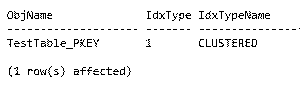
จะเห็นว่าเรายังไม่ได้สั่งสร้าง Index แต่ระบบได้สร้าง Clustered Index
(หรือเรียกว่าเปลี่ยนโครงสร้างจาก Heap ไปเป็น Clustered Index จะถูกต้องกว่า)
บนตาราง TEST.TestTable_PKEY ให้เราโดยอัตโนมัติ
ผู้เขียนจะแสดง Objects ภายใต้ตาราง TEST.TestTable_PKEY เฉพาะส่วนของ Indexes ผ่าน SSMS (SQL Server Management Studio)
ให้เห็นดังนี้
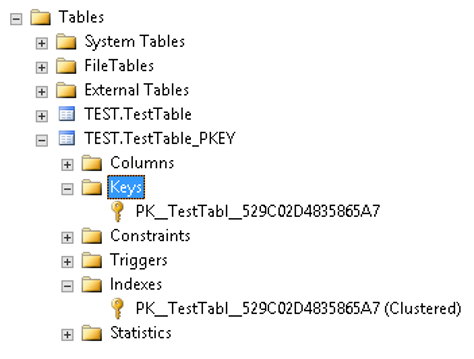
จะเห็นว่าภายใต้ Folder ชื่อว่า Indexes มี Indexes ชื่อเดียวกันกับ Primary Key ปรากฏอยู่
ตัวอย่างที่ผู้เขียนทดสอบแสดงให้เห็นว่าโครงสร้างตารางมีการจัดสรรแบบ Heap ได้
แต่หากผู้พัฒนาฐานข้อมูลมีการสร้าง Primary Key Constraint บนตารางนั้น
ระบบก็จะนำ Primary Key ไปสร้างเป็น Clustered Key ของ Clustered Index ทันที
เหตุที่เป็นเช่นนี้เพราะ Microsoft เกรงว่าคนจะลืมสร้าง Clustered Index กัน แล้วปล่อยตารางให้มีการจัดสรรแบบ Heap เอาไว้ (
มีประเภทข้อมูลน้อยมากที่ได้ประโยชน์จากการจัดสรรแบบ Heap มากกว่า Clustered Index) จึงถือวิสาสะสร้างให้เลยโดยอัตโนมัติ
ถ้าอยากใช้คอลัมน์อื่นที่ไม่ใช่คอลัมน์ที่เป็น Primary Key มาสร้างเป็น Clustered Key ล่ะเป็นไปได้หรือไม่?
คำถามนี้ถูกใช้ผู้เขียนเป็นอย่างมาก เพราะผู้เขียนได้รับการถ่ายทอดเรื่อง Clustered Index จากทาง Microsoft เอง
เมื่อสมัยที่ไม่ถูกสร้างอัตโนมัติพร้อมกับการสร้าง Primary Key (ราว ๆ Microsoft SQL เวอร์ชั่น 7-2000)
บอกว่า Clustered Index นั้นเป็นของสงวน (คือมีตัวเดียวอันเดียว) ต้องเลือกกันอย่างรอบคอบ
ผู้เขียนจะทดสอบว่าเป็นของสงวนจริงหรือไม่ ดังนี้
USE TestDB;
GO
DROP TABLE TEST.TestTable_PKEY;
CREATE TABLE TEST.TestTable_PKEY
(
Column1 varchar(10) NOT NULL PRIMARY KEY
, Column2 varchar(10) NOT NULL
);
GO
CREATE CLUSTERED INDEX CTIDX_NO2 ON TEST.TestTable_PKEY(Column2);ดังนั้น Clustered Index จะถูกสร้างตาม Primary Key Constraint โดยอัตโนมัติจากนั้น
ผู้เขียนได้ลองพยายามสร้าง Clustered Index เข้าไปเพิ่มดังคำสั่งล่างสุด ผลลัพธ์ที่ได้คือ

ข้อความแสดง Error บอกว่า ไม่สามารถสร้าง Clustered Index บนตารางได้มากกว่าหนึ่งตัว ซึ่งต้อง Drop ของเก่าทิ้งไปก่อนถึงจะสร้างใหม่ได้
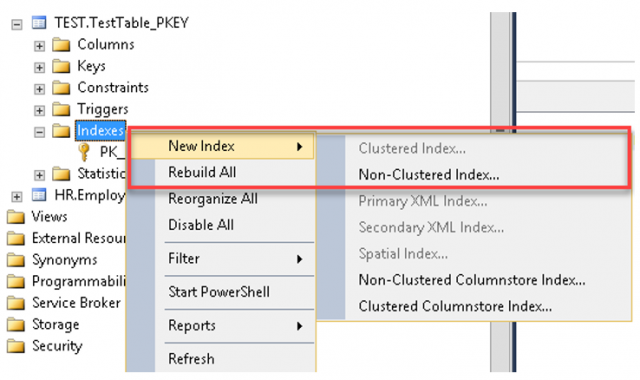
เช่นเดียวกับบน SSMS หากคลิกไปที่ Folder ชื่อว่า Indexes ภายใต้ตาราง TEST.TestTable_PKEY แล้วเลือก New Index
หากมีการสร้าง Clustered Indexed ไปแล้ว ก็จะไม่สามารถสร้างได้อีก
นี่เป็นเครื่องยืนยันว่า Clustered Index เป็นของสงวนมีได้เพียงอันเดียวต่อตารางเท่านั้น
เหตุผลผู้เขียนก็ได้เน้นย้ำไปแล้วว่าเรื่องนี้เป็นเรื่องของการจัดสรรข้อมูลในตาราง
ซึ่งมีได้เพียง เป็น Heap หรือเป็น Clustered Index อย่างใดอย่างหนึ่งเท่านั้น
และการจัดสรรก็จะมี 2 การจัดสรรไม่ได้ (การจัดสรรในที่นี้ คือ Table Allocation) ทำให้เมื่อมี Clustered Index บนตารางแล้วจะมีอีกไม่ได้
ส่วนที่อยากให้ Primary Key Constraint อยู่บนคอลัมน์หนึ่ง และ Clustered Key อยู่อีกคอลัมน์หนึ่งต่างจาก Primary Key จะต้องทำอย่างไร
เรื่องนี้มีเทคนิคอยู่นิดหน่อย เพราะหากสร้าง Primary Key ตัว Clustered Index ก็จะถูกสร้าง
พอเราลบ Clustered Index ปรากฏว่า Primary Key ก็จะถูกลบตามไปด้วยอีก
ดังนั้นเราจึงควรสร้างตารางโดยไม่มี Primary Key Constraint (ให้ตารางเป็น Heap ไว้ก่อน)
ขั้นตอนต่อมา คือ สร้าง Clustered Index และสุดท้ายค่อยสร้าง Primary Key Constraint ดังแสดง
USE TestDB;
GO
CREATE TABLE TEST.TestTable_CKEY_PKEY
(
Column1 varchar(10) NOT NULL
, Column2 varchar(10) NOT NULL
);
GO
CREATE CLUSTERED INDEX CTIDX_NO2 ON TEST.TestTable_CKEY_PKEY(Column2);
GO
ALTER TABLE TEST.TestTable_CKEY_PKEY
ADD CONSTRAINT PK_Column1 PRIMARY KEY (Column1);
GOหรืออีกแบบหนึ่งคือบังคับให้ Primary หลบไปใช้ Non-Clustered Index แทน
แล้วสร้าง Clustered Index ตามมาภายหลัง ดังแสดง
USE TestDB;
GO
CREATE TABLE TEST.TestTable_CKEY_PKEY
(
Column1 varchar(10) NOT NULL CONSTRAINT PK_Column1 PRIMARY KEY NONCLUSTERED
, Column2 varchar(10) NOT NULL
);
GO
CREATE CLUSTERED INDEX CTIDX_NO2 ON TEST.TestTable_CKEY_PKEY(Column2);
GOเมื่อดูผ่าน SSMS จะเห็นว่า Clustered Index ก็ถูกสร้าง (ในที่นี้ Clustered Key คือ Column2)
ในขณะที่ Primary Key ก็ถูกสร้างบน Column1 ซึ่งกลายเป็น Non-Clustered Index แทนดังรูป
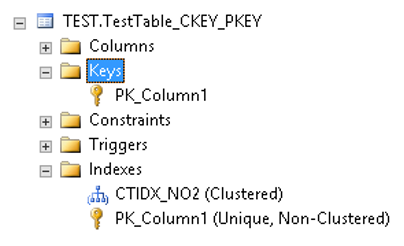
การจัดสรรแบบ Heap บน Microsoft SQL Server ที่บอกว่ามักไม่ค่อยมีประสิทธิภาพ (อาจไม่ใช่ทุกกรณี) ถ้าเทียบกับ Clustered Index
ก็เพราะ Heap นั้นมีวิธีการเอาแถวข้อมูลใส่ลงใน Page ข้อมูลแบบ PFS (Page Free Space) ซึ่งเป็นวิธีง่ายๆ
คือ เมื่อต้องการ Insert แถวข้อมูลก็จะหา Page ของตารางนั้น ๆ ที่ใกล้ที่สุดแล้วมีพื้นที่เพียงพอที่ใส่แถวข้อมูลก็จะบันทึกลง
ลองคิดตามนะครับ หากดิสก์นี้มีความจุ 1 TB และเราให้ Data File ของฐานข้อมูลของเราใชเต็มขนาดดิสก์
เบื้องหลังจากมีการแบบ 1 TB ออกเป็น Pages ย่อยขนาด 8060 Bytes ซึ่งแต่ละ Pages จะใส่ข้อมูลจากต่างตารางหรือต่าง Index ไม่ได้
(Pages เป็นหน่วยย่อยที่สุด เอาไว้เก็บข้อมูลของตารางหรือ Index เท่านั้น)
และใส่แถวข้อมูลลงไปได้ต้องมีพื้นที่เหลือให้บรรจุได้เต็มแถว แถวข้อมูลไม่สามารถอยู่ 2 Pages ได้
(เช่นครึ่งหนึ่งอยู่ใน Page หนึ่ง อีกครั้งอยู่อีก Page หนึ่ง แบบนี้ทำไม่ได้) ต้องทิ้งพื้นที่นั้นไป นี่แค่ข้อจำกัดบางข้อเอง
ผู้อ่านอ่านมาถึงตรงนี้คงจินตนาการออกนะครับว่าบรรดา Pages ที่เก็บข้อมูลตารางเดียวกันอาจกระจัดกระจายไปทั่วดิสก์ก็เป็นได้
และหัวอ่านใกล้ Page ไหนที่มีพื้นที่ว่างพอจะบันทึกแถวข้อมูลลงก็เขียนเลย หากผู้เขียนต้องการหาข้อมูลก็จำเป็นต้อง Scan หาจนกว่าจะเจอ
แต่สำหรับการจัดสรรโครงสร้างตารางด้วย Clustered Index ข้อมูลจะมีการเรียงลำดับตาม Clustered Key ไว้ก่อน
หมายถึง Pages ข้อมูลของตารางเดียวกันก็จะมีการเรียงลำดับ และแถวข้อมูลใน Page ก็จะมีการเรียงลำดับด้วย
ผู้เขียนจะทดสอบโครงสร้างตารางแบบ Heap และ Clustered Index ให้เห็นเมื่อใส่ข้อมูลลงไป ดังนี้
กรณี HEAP
USE TestDB;
GO
CREATE TABLE TEST.TestTable
(
Column1 varchar(10) NOT NULL
, Column2 varchar(10) NOT NULL
);
GO
INSERT TEST.TestTable
VALUES ('X','11'),('F','55'),('R','32'),('H','94'),('M','63');
GO
SELECT * FROM TEST.TestTable;
GO
ผลลัพธ์ที่ได้

จะเห็นว่าในตอนที่โครงสร้างตารางมีการจัดสรรแบบ Heap เมื่อให้แถวข้อมูลลงไปมีลำดับอย่างไร เมื่อสืบค้นข้อมูลออกมาก็จะได้ข้อมูลมีลำดับเหมือนที่ใส่เข้าไป
กรณี Clustered Index
USE TestDB;
GO
CREATE CLUSTERED INDEX TestTBL_CIdx ON TEST.TestTable(Column1);
GO
SELECT * FROM TEST.TestTable;
GOผลลัพธ์ที่ได้
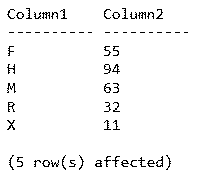
หากเปลี่ยนให้มีการจัดสรรแบบ Clustered Index จึงสังเกตเห็นว่าแถวข้อมูลจะมีการจัดเรียงใหม่ในระดับโครงสร้างจริง ๆ ตาม Column1 ซึ่งเป็น Clustered Key
ผู้เขียนจะทดลองเพิ่มเติมโดยการเปลี่ยนโครงสร้างจาก Clustered Index กลับมาเป็น Heap แล้วใส่แถวข้อมูลเพิ่มดังตัวอย่าง
USE TestDB;
GO
DROP INDEX TestTBL_CIdx ON TEST.TestTable;
GO
INSERT TEST.TestTable
VALUES ('A','22'),('U','22');
SELECT * FROM TEST.TestTable;
GOผลลัพธ์ที่ได้

จะเห็นว่าโครงสร้างข้อมูลที่เคยถูกเรียงตาม Clustered Key เดิม (Column1) ก็อยู่ในลักษณะเรียง แต่แถวข้อมูลที่ใส่เพิ่มเข้าไปจะไปต่อท้ายแทนแบบลักษณะของ Heap นั่นเอง
ผู้อ่านคงพอเข้าใจการจัดสรรโครงสร้างตารางแบบ Heap และ Clustered Index ที่ผู้เขียนปูทางมาให้อย่างค่อยเป็นค่อยไป
ผู้อ่านสามารถทดลองเอง แต่ต้องทำตามลำดับจากบนลงล่าง แล้วลองดูผลลัพธ์ด้วยตนเองก็น่าจะเข้าใจได้ไม่ยาก
Non-Clustered Index ล่ะคืออะไร
เวลา Query นั้น บรรดาเงื่อนไขการ Join เอย, Predicate ที่อยู่ใน WHERE เอย (หรือบางท่านแบบเป็นเงื่อนไขการ Filter)
หากทำกับตารางที่มีการจัดสรรแบบ Heap ผลที่ได้จะเป็นอย่างไร ผู้เขียนของแสดงผ่าน Estimate Execution Plan ดังนี้
SELECT
*
FROM TEST.Customers as C
INNER JOIN TEST.Orders as O
ON C.CustID=O.CustID
WHERE C.custID=98; 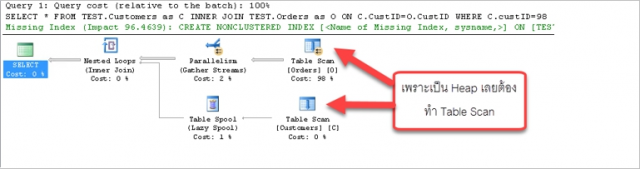
จากตัวอย่าง ตาราง TEST.Customers และตาราง TEST.Orders นั้นมีการจัดสรรโครงสร้างแบบ Heap
จึงต้องทำการ Scan ตารางทั้งสองตั้งแต่แถวข้อมูลแรกไปจนแถวสุดท้ายในตารางไม่ว่าจะมีกี่ Pages ข้อก็ตาม
(เพราะโครงสร้างแบบ Heap นั้นแถวข้อมูลภายใน Page ก็ไม่มีลำดับ และแต่ละ Pages ก็ไม่มีลำดับ เลยต้อง Scan หมด)
เพื่อนำเอาข้อมูลมา Matching กันผ่าน Nested Loops (ไว้มีโอกาสผู้เขียนจะเล่าวิธีการวิเคราะห์ผลของ Execution Plan ให้อ่านกัน)
ผู้อ่านอาจจะบอกว่าสำหรับตาราง Customers เมื่อ Scan ไปจนพบแถวข้อมูลที่ CustID=98 แล้วก็น่าจะหยุด Scan
ในตัวอย่างนี้ผู้เขียนไม่ได้กำหนดให้ CustID เป็น Primary Key ดังนั้นถึงพบแล้วก็ยังต้อง Scan ต่อไป เพราะไม่มีอะไรรับประกันได้ว่า CustID=98 มีแถวข้อมูลเดียว
จากนั้นผู้อ่านได้ลองสร้าง Clustered Index ผ่านการกำหนด Primary Key Constraint ให้กับทั้งสองตาราง ดังแสดง
USE TestDB;
GO
ALTER TABLE TEST.Customers
ADD CONSTRAINT PK_Customers PRIMARY KEY (CustID);
GO
ALTER TABLE TEST.Orders
ADD CONSTRAINT PK_Orders PRIMARY KEY (OrderID);
GO
แล้วทดลองหา Estimate Execution Plan ใหม่ดังนี้
SELECT
*
FROM TEST.Customers as C
INNER JOIN TEST.Orders as O
ON C.CustID=O.CustID
WHERE C.custID=98; 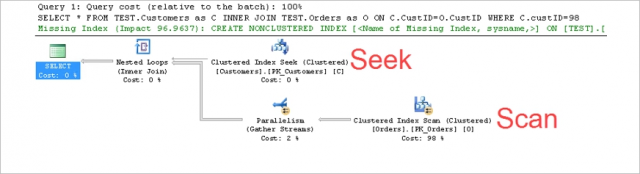
จะเห็นว่าคราวนี้ในฝั่งตาราง TEST.Customers การดำเนินการที่เกิดขึ้นคือ Clustered Index Seek
พอเห็นคำว่า Seek แสดงว่ามีการ Search ตามกลไกของ Index แต่สำหรับตาราง TEST.Orders
การดำเนินการ คือ Clustered Index Scan ซึ่งถือว่าไม่ได้ใช้กลไกของ Index ทำเหมือน Table (Heap) Scan
แต่ที่ไม่ขึ้นแสดงว่าเป็น Table Scan ก็เพราะเราเปลี่ยนการจัดสรรจาก Heap มาเป็น Clustered Index แล้ว การดำเนินการเลยเปลี่ยนชื่อใหม่เท่านั้น
คราวนี้ผู้เขียนจะลองเพิ่ม Non-Clustered Index ที่ตรงกับเงื่อนไขการ JOIN เข้าไปในตาราง TEST.Orders ดังแสดง
USE TestDB
GO
CREATE NONCLUSTERED INDEX NCTIdx_CustID ON TEST.Orders(custid);
GOแล้วทดลองหา Estimate Execution Plan ใหม่ดังนี้
SELECT
*
FROM TEST.Customers as C
INNER JOIN TEST.Orders as O
ON C.CustID=O.CustID
WHERE C.custID=98; 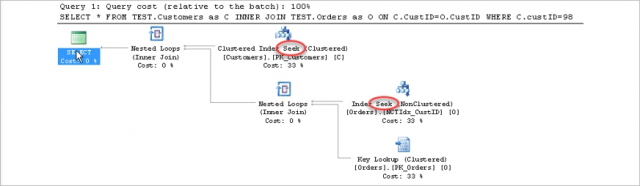
จะเห็นว่าแม้เราจะมี Clustered Index อยู่แล้วก็ตาม แต่เงื่อนไขการ JOIN หรือ Predicate ในจุดอื่น ๆ ของการ Query ไม่ได้ใช้ส่วนของ Clustered Index เลย
การดำเนินการก็จะเป็นเพียง Clustered Index Scan ซึ่งเป็นการ Scan บนโครงสร้างของ Clustered Index แทนที่จะ Scan โครงสร้างของ Heap
เราจึงจำเป็นต้องนำ Non-Clustered Index มาช่วย
สำหรับ Non-Clustered Index ไม่ได้ช่วยบนโครงสร้าง Clustered Index แต่กับ Heap ก็ช่วยได้มากเช่นกัน ผู้เขียนจะสรุปในตารางต่อไปนี้
| Non-Clustered Index บนโครงสร้าง Heap | Non-Clustered Index บนโครงสร้าง Clustered Index |
ในระดับ LEAP Level ของ Non-Clustered Index จะมีตัวชี้ไปยังตารางที่มี โครงสร้างแบบ Heap ระบุถึงข้อมูลโดย
| ในระดับ LEAP Level ของ Non-Clustered Index จะมีตัวชี้ไปยังตารางที่มีโครงสร้างแบบ Clustered Index ระบุถึงข้อมูลโดย
|
สำหรับ Non-Clustered Index นั้นเราสามารถมีจำนวนเท่าไหร่ก็ได้ในตาราง เพราะเป็นการสร้างแยกออกจากโครงสร้างตารางแล้ว
ทำการชี้กลับมายังตารางตามตารางที่สรุปให้ แต่การสร้างเพิ่มนั้นอาจก่อให้เกิด ภาระงานเพิ่มขึ้น พื้นที่จัดเก็บที่เพิ่มตามจำนวนของ Index
เช่น เราสร้าง Non-Clustered Index จาก 2 คอลัมน์ ก็จะใช้พื้นที่จัดเก็บเท่ากับทุกแถวข้อมูลใน 2 คอลัมน์นั้นไปสร้างเป็นโครงสร้าง Index
บวกด้วยข้อมูลตัวชี้ ถ้าเพิ่ม Non-Clustered Index ก็ทำแบบนี้เพิ่มอีก ก็เปลืองพื้นที่จัดเก็บเพิ่ม
การมี Non-Clustered Index จำนวนมาก อาจจะช่วยในการแง่ของการ Query ให้มีประสิทธิภาพดียิ่งขึ้น
แต่กับการปรับปรุงข้อมูลในตารางผ่านคำสั่ง Insert, Update และ Delete กลับให้ผลตรงกันข้าม
เพราะหากมีการ Insert แถวข้อมูลเข้าในตาราง ก็ต้องเพิ่มใน Non-Clustered Index ตามไปด้วย
และไม่ใช่เรื่องง่าย ข้อมูลใน Non-Clustered Index มีการจัดลำดับไว้แล้ว
หากข้อมูลที่เข้ามาใหม่จำเป็นต้องแทรกเพื่อให้อยู่ในลำดับที่ถูกต้อง ก็จำเป็นต้องมีการ Split Page ข้อมูล Index นั้นขึ้นเกิดเป็นภาระงาน
การ Update แถวข้อมูลก็เช่นกัน หากการ Update กระทำกับคอลัมน์ที่นำไปสร้าง Non-Clustered Index ก็ต้องตามไปปรับปรุงใน Index ด้วย
ก็จะเกิดทั้งการ Mark ว่าถูกลบ แล้วย้ายไปอยู่ในลำดับที่ถูกต้อง ก็จะเกิดการ Split Page อีกนั่นเอง
ส่วนกรณี Delete อาจจะง่ายกว่าเขาเพื่อน เมื่อมีการลบข้อมูลในตาราง ก็จะมาลบใน Non-Clustered Index ด้วย
แต่เป็นเพียงการ Mark ว่าถูกลบลงไปเฉย ๆ แต่ก็ถือว่ายังมีภาระงานเพิ่มขึ้นอยู่ดี
โดยสรุป ก็คือ Non-Clustered Index ช่วยให้ Query ข้อมูลเร็วขึ้นได้
แต่หากมีจำนวนมากก็จะเพิ่มภาระทั้งในการ Insert, Update และ Delete ข้อมูล แล้ว เราจะรู้ได้อย่างไร วัดมีมากน้อยเท่าไหร่ถึงจะเหมาะสม
ผู้เขียนขอแนะนำให้ใช้เครื่องมือที่ชื่อว่า Database Engine Tuning Advisor ช่วยในการวิเคราะห์ ซึ่งสามารถเรียกใช้ผ่านเมนู Tools บน SSMS
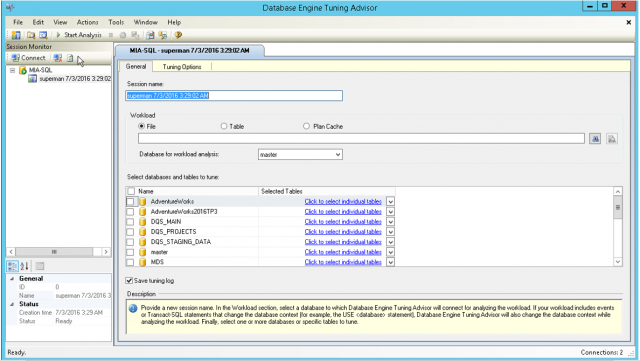
เครื่องมือนี้จะช่วยในการวิเคราะห์และแนะนำ Indexes และ Statistics ที่เหมาะสมให้กับเรา
(นอกเหนือจาก Index และ statistics แล้วยังมีเรื่องของวางแผนทางกายภาพต่าง ๆ อีกด้วย)
ซึ่งคำแนะนำมักพบอยู่บ่อยครั้งที่ให้ลบ Indexes ทิ้งไปแทนที่จะแนะนำให้สร้าง Indexes
เพราะเครื่องมือนี้จะอาศัยสิ่งที่เรียกว่า Workload ซึ่งเป็นได้ทั้ง Trace File, Trace Table
หรือจาก Execution Plan ที่ Cache ไว้ในกลไกของ Query Optimization
สำหรับ Trace File หรือ Trace Table นั้น จะได้จากเครื่องมือชื่อ SQL Profiler หรือ SQLTrace (ผ่าน Stored Procedure ภายใน Database Engine)
กรณีที่สร้างจาก SQL Profiler จะมี Template ที่ชื่อว่า Tuning ให้เลือกใช้ได้เลย ดังแสดง
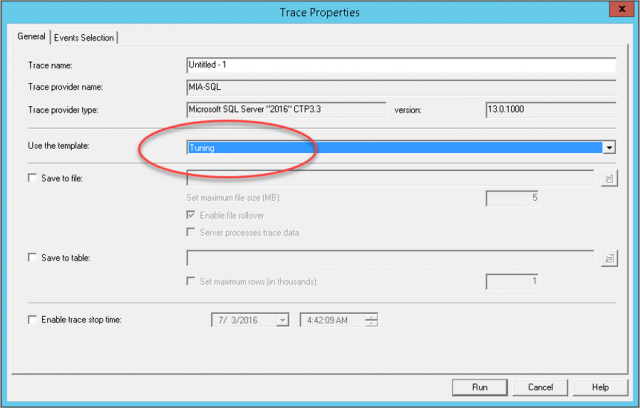
ใน Template นี้จะเก็บ Statement ต่าง ๆ เก็บการประมวลผล Stored Procedures นำทุกอย่างมาวิเคราะห์
ซึ่งหากเราได้กลุ่มตัวอย่างหลากหลายพอเช่นไม่ได้มีแต่ SELECT แต่ยังเก็บคำสั่งอื่น ๆ อาทิ Insert, Update ,Delete มาได้ด้วย
ก็อาจจะได้คำแนะนำมากกว่าการสร้าง Index ก็เป็นได้ และหากมีคำแนะนำให้ลบเกิดขึ้นเราควรเชื่อหรือไม่
ผู้เขียนตอบได้เลยว่าควรเชื่อ เพราะปกติไม่มีใคร Query โดยบังคับว่าจะใช้ Indexes ตัวที่เราสร้างลงไปใน SELECT
(ถึงแม้จะกระทำได้ผ่านทาง Table Hint ก็ตาม) ปกติแล้ว Microsoft SQL จะเอาข้อมูลของ Indexes และ Statistics ไปสร้างเป็น Plan ออกมาหลาย ๆ Plan
แล้วพิจารณาเลือก Plan ที่เสีย Cost น้อยสุดมาใช้ในการ Execute เมื่อ Plan ไหนเข้าตาก็จะ Cache ไว้ใน Memory เพื่อลดขั้นตอนของ Query Execution ลง
เห็นไหมครับว่าเราสร้าง Indexes ออกมามากมาย แต่กลไกการเลือกใช้เป็นของ Database Engine
ดังนั้นเมื่อ Database Engine บอกว่าให้ลบทิ้งแสดงว่าร้อยวันพันปีอาจไม่เคยใช้ อาจใช้น้อยมาก อาจเพิ่มภาระงาน
สิ่งเหล่านี้ระบบเก็บไว้หมด หากระบบแนะให้ลบทิ้งจึงควรทำตาม โดยรูปภาพสุดท้าย คือ ตัวอย่างคำแนะนำจาก Database Engine Tuning Advisor
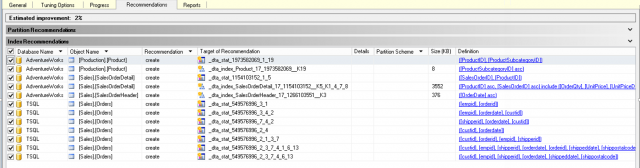
ซึ่งจะมีคำแนะนำว่าให้ลง หรือ สร้างในคอลัมน์ Recommendation
และสามารถดู Definition พร้อมดำเนินการได้ทันที นับเป็นเครื่องมือที่มีประสิทธิภาพ และใช้งานได้ไม่ยาก
บทสรุป
แต่หากใช้ไม่เป็นก็อาจจะทำให้เปลืองพื้นที่ หรือทำงานได้ช้าเช่นกัน
ดังนั้นจำเป็นที่จะต้องมีความรู้ความเข้าใจในเรื่องของ SQL Server Index ให้ดี และได้เรียนรู้จักกับโปรแกรม SQL Server Profiler, SQL Server Database Engine Advisor อีกด้วย
เพื่อที่จะช่วยแนะนำการปรับแต่งฐานข้อมูลให้ได้ประสิทธิภาพมากยิ่งขึ้น