




ความสำคัญของการแปลงข้อมูลในรูปแบบ One-Hot Encoding ในการวิเคราะห์สถิติ

ความสำคัญของการแปลงข้อมูลในรูปแบบ One-Hot Encoding ในการวิเคราะห์สถิติ
ในกระบวนการวิเคราะห์ข้อมูลด้วยเทคนิคทางสถิติและการเรียนรู้ของเครื่อง (Machine Learning) เช่น การวิเคราะห์ถดถอย (Regression Models), การจัดกลุ่มข้อมูล (Clustering), การตัดสินใจเชิงต้นไม้ (Decision Trees) รวมถึงอัลกอริธึมอื่น ๆ นั้น โดยพื้นฐานแล้ว โมเดลเหล่านี้ส่วนใหญ่มักต้องการข้อมูลที่อยู่ในรูปแบบเชิงตัวเลข (Numeric Data) เพื่อทำการคำนวณและวิเคราะห์เชิงคณิตศาสตร์ได้อย่างถูกต้องและมีประสิทธิภาพ
อย่างไรก็ตาม ในการใช้งานจริง ข้อมูลที่ได้รับมักมีลักษณะเป็นข้อความ (Categorical Data) โดยเฉพาะในคอลัมน์ที่แสดงถึงหมวดหมู่หรือประเภท เช่น ชื่อสินค้า ประเภทสินค้า หรือประเทศของลูกค้า ซึ่งไม่สามารถนำไปใช้กับโมเดลเชิงตัวเลขได้โดยตรงดังนั้น การแปลงข้อมูลประเภทข้อความให้อยู่ในรูปแบบเชิงตัวเลขจึงเป็นขั้นตอนสำคัญก่อนนำข้อมูลเข้าสู่กระบวนการวิเคราะห์ หนึ่งในวิธีที่นิยมและมีประสิทธิภาพสูงคือการใช้ One-Hot Encoding ซึ่งเป็นเทคนิคที่แปลงค่าหมวดหมู่ให้กลายเป็นคอลัมน์ตัวแปรหลายตัว โดยกำหนดค่าตัวเลข “1” ให้กับหมวดหมู่ที่สอดคล้อง และ “0” กับหมวดหมู่อื่น เพื่อให้โมเดลสามารถตีความข้อมูลเหล่านี้ได้ในเชิงคณิตศาสตร์โดยไม่เกิดอคติจากลำดับหรือขนาดของตัวเลข
การใช้ One-Hot Encoding จึงมีบทบาทสำคัญอย่างยิ่งในการเตรียมข้อมูลก่อนการวิเคราะห์ และช่วยให้โมเดลสามารถประมวลผลข้อมูลได้แม่นยำและตรงตามวัตถุประสงค์ทางสถิติที่ตั้งไว้

pip install pandas openpyxl
- สร้างไฟล์ Python ขึ้นมาโดยแนะนำให้เขียน code ผ่าน Visual Studio Code โดยมี code ดังนี้
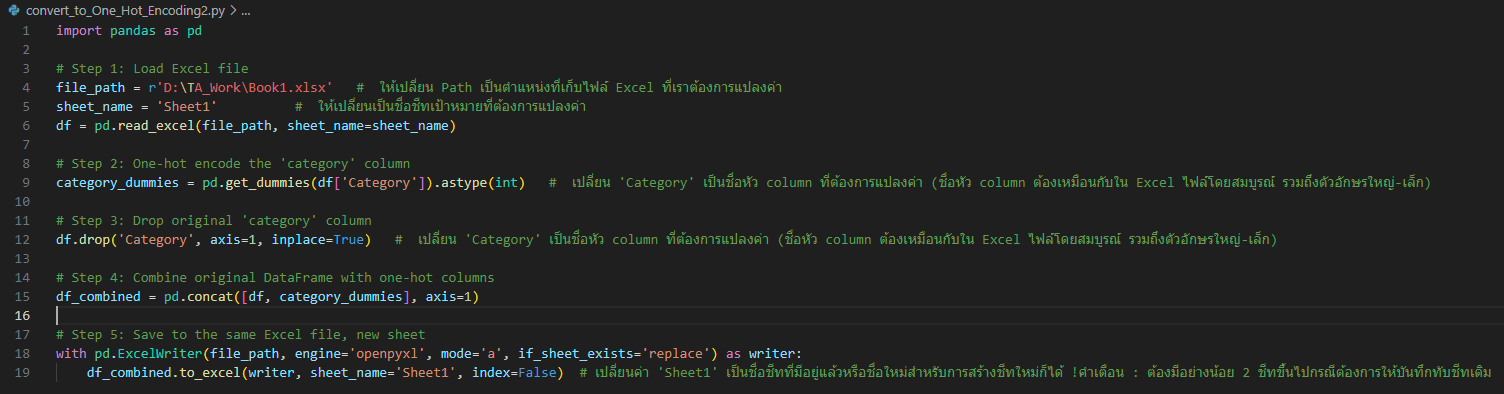
import pandas as pd
# Step 1: Load Excel file
file_path = r'D:\TA_Work\Book1.xlsx' # ให้เปลี่ยน Path เป็นตำแหน่งที่เก็บไฟล์ Excel ที่เราต้องการแปลงค่า
sheet_name = 'Sheet1' # ให้เปลี่ยนเป็นชื่อชีทเป้าหมายที่ต้องการแปลงค่า
df = pd.read_excel(file_path, sheet_name=sheet_name)
# Step 2: One-hot encode the 'category' column
category_dummies = pd.get_dummies(df['Category']).astype(int) # เปลี่ยน 'Category' เป็นชื่อหัว column ที่ต้องการแปลงค่า (ชื่อหัว column ต้องเหมือนกับใน Excel ไฟล์โดยสมบูรณ์ รวมถึงตัวอักษรใหญ่-เล็ก)
# Step 3: Drop original 'category' column
df.drop('Category', axis=1, inplace=True) # เปลี่ยน 'Category' เป็นชื่อหัว column ที่ต้องการแปลงค่า (ชื่อหัว column ต้องเหมือนกับใน Excel ไฟล์โดยสมบูรณ์ รวมถึงตัวอักษรใหญ่-เล็ก) # Step 4: Combine original DataFrame with one-hot columns
df_combined = pd.concat([df, category_dummies], axis=1)
# Step 5: Save to the same Excel file, new sheet
with pd.ExcelWriter(file_path, engine='openpyxl', mode='a', if_sheet_exists='replace') as writer: df_combined.to_excel(writer, sheet_name='Sheet1', index=False) # เปลี่ยนค่า 'Sheet1' เป็นชื่อชีทที่มีอยู่แล้วหรือชื่อใหม่สำหรับการสร้างชีทใหม่ก็ได้ !คำเตือน : ต้องมีอย่างน้อย 2 ชีทขึ้นไปกรณีต้องการให้บันทึกทับชีทเดิม
- หลังจาก paste code ดังกล่าวและแก้ไข path file, sheet name และ column name แล้ว ก็สามารถทำการรัน code ได้เลยจะได้ผลลัพธ์ดังรูป
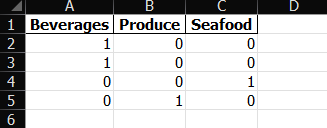
จากที่กล่าวมาข้างต้น จะเห็นได้ว่าการแปลงข้อมูลจากรูปแบบข้อความให้เป็นข้อมูลเชิงตัวเลข โดยเฉพาะในรูปแบบของ One-Hot Encoding ถือเป็นขั้นตอนพื้นฐานที่จำเป็นอย่างยิ่งในกระบวนการวิเคราะห์ข้อมูลด้วยเทคนิคทางสถิติและการเรียนรู้ของเครื่อง การจัดเตรียมข้อมูลในลักษณะนี้ไม่เพียงแต่ช่วยให้โมเดลสามารถประมวลผลข้อมูลประเภทหมวดหมู่ได้อย่างถูกต้องเท่านั้น แต่ยังช่วยลดความคลาดเคลื่อนที่อาจเกิดขึ้นจากการตีความข้อมูลเชิงข้อความด้วยเทคนิคทางสถิติและการเรียนรู้ของเครื่อง
นอกจากนี้ One-Hot Encoding ยังช่วยให้สามารถเปรียบเทียบ วิเคราะห์ และจำแนกความสัมพันธ์ระหว่างตัวแปรในกลุ่มข้อมูลได้อย่างแม่นยำมากยิ่งขึ้น ซึ่งส่งผลโดยตรงต่อคุณภาพของแบบจำลองทางสถิติและผลลัพธ์ที่ได้จากการวิเคราะห์
ดังนั้น การให้ความสำคัญกับการแปลงข้อมูลประเภทข้อความให้เหมาะสมกับการใช้งานของโมเดลจึงเป็นสิ่งจำเป็นในการวางแผนและออกแบบกระบวนการวิเคราะห์ข้อมูล
นอกจากนี้ One-Hot Encoding ยังช่วยให้สามารถเปรียบเทียบ วิเคราะห์ และจำแนกความสัมพันธ์ระหว่างตัวแปรในกลุ่มข้อมูลได้อย่างแม่นยำมากยิ่งขึ้น ซึ่งส่งผลโดยตรงต่อคุณภาพของแบบจำลองทางสถิติและผลลัพธ์ที่ได้จากการวิเคราะห์
ดังนั้น การให้ความสำคัญกับการแปลงข้อมูลประเภทข้อความให้เหมาะสมกับการใช้งานของโมเดลจึงเป็นสิ่งจำเป็นในการวางแผนและออกแบบกระบวนการวิเคราะห์ข้อมูล
บทความที่เกี่ยวข้อง




Tags: