การอ่าน Query Execution Plan ตอนที่ 2
ก่อนหน้านี้ บทความ การอ่าน Query Execution Plan ตอนที่ 1 เป็นการปูพื้นฐานเกี่ยวกับชนิดของการแสดงผล Compiled Plan (Query Execution Plan ที่ถูกเลือกจากกลไก Query Optimization แล้ว) ทั้งแบบ Estimated และ Actual และตัวอย่างการสร้างและปรับแต่ง Index ชนิด Covering Index กันไปแล้ว
สำหรับ การอ่าน Query Execution Plan ตอนที่ 2 นี้ ผู้เขียนจะเจาะไปที่ตัวดำเนินการที่พบบ่อย รวมถึงความรู้เกี่ยวกับโครงสร้างตารางแบบต่าง ๆ กัน
พื้นฐานความรู้เกี่ยวกับโครงสร้างตาราง
แต่ละฐานข้อมูลบน Microsoft SQL Server ประกอบด้วยไฟล์ 2 ชนิด คือ
- Data Files และ
- Transaction Log File
ในบทความนี้ผู้เขียนขอเน้นไปที่ Data Files
Data Files
ฐานข้อมูลทั้งหมดไม่ว่าจะเป็นฐานข้อมูลระบบ หรือ ฐานข้อมูลที่ผู้ใช้สร้างขึ้น ต้องมี Data File อย่างน้อยหนึ่งไฟล์
โดย Data File แรก จะเป็นไฟล์หลักที่มีข้อมูลสำหรับเริ่ม Start ฐานข้อมูลขึ้นมา และ เก็บรายละเอียดของไฟล์อื่น ๆ ที่ใช้ในฐานข้อมูลเอาไว้
แนะนำให้ใช้ .mdf เป็นนามสกุลสำหรับ Data File แรก และ .ndf เป็นนามสกุลสำหรับไฟล์ลำดับถัดไป
Pages
Page เป็นหน่วยจัดเก็บพื้นฐานของ Microsoft SQL Server แต่ละ Pages มีขนาด 8 KB ไม่ว่าจะเป็นข้อมูลของ Tables หรือ ข้อมูลของ Indexes ล้านแล้วแต่เก็บลง Pages (Page อื่นนอกเหนือจาก Data Page และ Index
Page ผู้เขียนขอไม่นำมาพูดถึงในบทความนี้ สามารถอ่านได้จากลิ้งก์ https://docs.microsoft.com/en-us/sql/relational-databases/pages-and-extents-architecture-guide?view=sql-server-ver15)
Page นั้นหากถูกจับจองโดย Object ใด ก็จะเป็นของ Object นั้น เช่นถูกจับจองโดยตาราง HR.Employees ทั้ง Data Page นั้นก็จะบรรจุข้อมูลของตาราง HR.Employees
Extent
ในส่วน Memory Management ของ Microsoft SQL Server นั้นจะเข้าถึงข้อมูลระดับ Extent หรือพื้นที่บังคับ 8 Pages เรียงติดกัน ถือเป็น 1 หน่วย Extent มี 2 ประเภท คือ
- Mixed Extents เป็น Extents ที่หลาย ๆ Objects (Tables หรือ Indexes) ใช้ร่วมกัน เป็นเหมือนพื้นที่พักของบรรดา Pages ของ Objects ที่ยังใช้ไม่ครบ 8 Pages มากองรวมกันไว้ก่อน
- Uniform Extents ที่ถูกใช้โดย Object เดียว โดยบรรดา Pages ของ Object ใด ที่อยู่ใน Mixed Extents รวมกันได้ครบ 8 Pages ก่อน ก็จะเปลี่ยนมาใช้ Uniform Extent แทน
Microsoft SQL Server ในเวอร์ชั่นเก่าจนถึง Microsoft SQL Server 2014
สำหรับ Tables หรือ Indexes ที่เพิ่งสร้างขึ้นและมีข้อมูลน้อยจะเริ่มใช้งานจาก Mixed Extents ก่อน
ตั้งแต่ Microsoft SQL Server 2016 เป็นต้นไป
จะเป็น ฐานข้อมูลที่ผู้ใช้สร้างขึ้น จะเป็น Uniform Extents โดยตั้งต้น
ส่วน ฐานข้อมูลระบบ จะเป็น Mixed Extents โดยตั้งต้น
ยกเว้นเพียงฐานข้อ tempdb ที่ถูกบังคับให้เป็น Uniform Extents โดยตั้งต้น
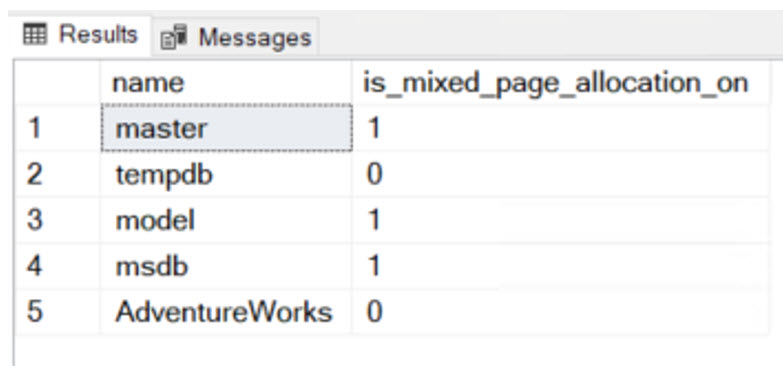
ผู้อ่านสามารถเรียกดูว่าฐานข้อมูลใด กำหนดให้ใช้ Mixed Extents บ้างจากคำสั่งต่อไปนี้
SELECT
name
, is_mixed_page_allocation_on
FROM sys.databases;
ผลลัพธ์ที่ได้ คือ
และหากพยายามจะบังคับให้ฐานข้อมูล tempdb เป็น Mixed Extents จากคำสั่งต่อไปนี้
ALTER DATABASE TempDB SET MIXED_PAGE_ALLOCATION ON;
จะไม่สามารถทำได้ ผลลัพธ์ที่ได้

ส่วนฐานข้อมูลที่ผู้ใช้สร้างขึ้นสามารถกำหนดได้ไม่มีปัญหาแต่อย่างใด
โครงสร้างตารางที่จำเป็นต่อการอ่าน Execution Plan
เมื่อเข้าใจว่า Page คืออะไรพอสมควรแล้ว
ผู้เขียนจะขอเล่าถึงโครงสร้างตารางแต่ละแบบของ Microsoft SQL Server เพื่อเป็นพื้นฐานในการอ่าน Query Execution Plan
โครงสร้างตารางแบบ HEAP
เมื่อมีการบันทึกข้อมูลลง Table จะบันทึกลง page ของ Table เป้าหมายที่มีพื้นที่ว่างเพียงพอ
(เวลาบันทึกจะต้องบันทึกได้เต็มแถวข้อมูล หากบันทึกได้ไม่เต็มแถวให้ไปหา page ใหม่ที่สามารถบันทึกลงได้เต็มแถว)
โดยการบันทึกแถวข้อมูลไม่มีการเรียงลำดับ และแต่ละ pages ของ Table เป้าหมายก็ไม่มีลำดับ
แน่นอนว่าพอใช้ไประยะเวลาหนึ่งข้อมูลที่จัดเก็บในโครงสร้างนี้จะกระจัดกระจาย เวลาสืบค้นน่าจะลำบาก
แต่เหมาะมากกับข้อมูลประเภทที่ต้องบันทึกลงอย่างเดียวด้วยความรวดเร็ว แต่ไม่คิดจะสืบค้นออกมาใช้งาน
ผู้เขียนจะทดสอบสร้างตารางที่มีโครงสร้างแบบ HEAP
โดยดึงข้อมูลจากฐานข้อมูล Adventureworks ไปใช้
หากผู้อ่านต้องการทำตามให้หาฐานข้อมูล Adventureworks จากลิ้งก์ต่อไปนี้
https://docs.microsoft.com/en-us/sql/samples/adventureworks-install-configure?view=sql-server-ver15 มา restore
CREATE DATABASE TestDB;
GO
USE TestDB;
GO
CREATE SCHEMA heap;
GO
CREATE TABLE heap.Person
(
BusinessEntityID int NOT NULL PRIMARY KEY NONCLUSTERED
, Title nvarchar(8) NULL
, FirstName nvarchar(50) NOT NULL
, MiddleName nvarchar(50) NULL
, LastName nvarchar(50) NOT NULL
);
จากตัวอย่างเป็นการสร้างตารางแบบ HEAP ผ่านการสร้าง Primary Key แบบ Non-Clustered Index
(เป็นเพียงแนวทางหนึ่งของการได้โครงสร้างตารางแบบ HEAP เท่านั้น)
จากนั้นผู้เขียนจะดึงข้อมูลจากตาราง Person.Person ในฐานข้อมูล Adventureworks ใส่ลงในตาราง heap.Person
INSERT INTO heap.Person
SELECT
BusinessEntityID
, Title
, FirstName
, MiddleName
, LastName
FROM AdventureWorks.Person.Person;
เมื่อทำการสืบค้นข้อมูลจากตาราง heap.Person จะพบว่าต้นทางมีโครงสร้างตารางเป็น HEAP
SELECT * FROM heap.Person;
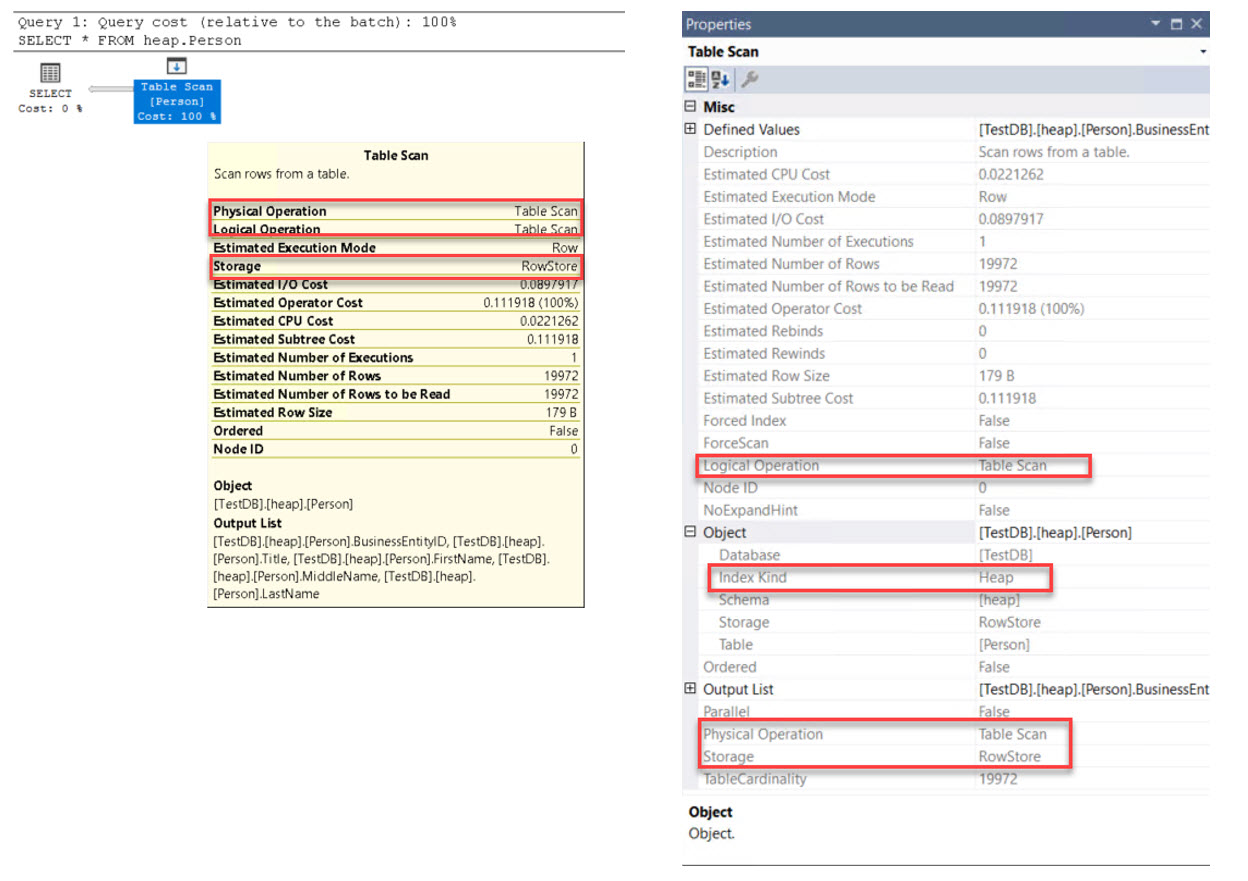
ตัวดำเนินการที่ทำให้รู้ว่าโครงสร้างตารางเป็น HEAP คือ Table Scan
และหากเข้าไปดูรายละเดียดของตัวดำเนินการโดยนำเมาส์ไปลอยเหนือตัวดำเนินการจะพบว่ามีแหล่งจัดเก็บเป็น Rowstore
หากผู้อ่านต้องการรายละเอียดที่มากขึ้น
สามารถคลิกขวาที่ตัวดำเนินการ Table Scan
แล้วเลือก Properties จะพบว่าชนิดของ Index เป็น HEAP
โครงสร้างตารางแบบ Row-Based Clustered
เป็นโครงสร้างตารางแบบ Row-Based ที่ไม่ใช่ HEAP
เรามักเรียกว่า Clustered Index ทำให้เข้าใจไปว่ามันคือ Index แบบหนึ่ง
แต่ที่จริงแล้วเป็นโครงสร้างตารางที่ผสมความเป็น Index อยู่ในตัวเองด้วย
โดยจะเลือกคอลัมน์ขึ้นมาเป็น Clustered Key
เมื่อมีการบันทึกข้อมูลลง Table จะบันทึกลง page ของ Table โดยเรียงลำดับแถวข้อมูลตาม Clustered Key ที่เลือกไว้
(เวลาบันทึกจะต้องบันทึกได้เต็มแถวข้อมูล หากบันทึกได้ไม่เต็มแถวให้บันทึกลงใน page ลำดับถัดไปที่สามารถบันทึกลงได้เต็มแถว หรือหากจำเป็นต้องแทรกแถวข้อมูลเพื่อให้เรียงตาม Clustered Key ก็จะเกิดการ Split Page ขึ้น)
โครงสร้างตารางแบบนี้จะมีการเรียงลำดับแถวข้อมูลในแต่ละ Page ตามลำดับของ Clustered Key และ Page แต่ละ Page ก็เรียงตามลำดับของ Clustered Key เช่นกัน
ผู้เขียนจะทดสอบสร้างตารางที่มีโครงสร้างแบบ Row-Based Clustered
USE TestDB;
GO
CREATE SCHEMA cluster;
GO
CREATE TABLE cluster.Person
(
BusinessEntityID int NOT NULL PRIMARY KEY
, Title nvarchar(8) NULL
, FirstName nvarchar(50) NOT NULL
, MiddleName nvarchar(50) NULL
, LastName nvarchar(50) NOT NULL
);
จากตัวอย่างเป็นการสร้างตารางแบบ Clustered ผ่านการสร้าง Primary Key Clustered Index
(โดยตั้งต้นจะสร้าง Clustered Key จากคอลัมน์ที่เลือกเป็น Primary Key และเป็นเพียงแนวทางหนึ่งของการได้โครงสร้างตารางแบบ Clustered เท่านั้น)
จากนั้นผู้เขียนจะดึงข้อมูลจากตาราง Person.Person
ในฐานข้อมูล Adventureworks ใส่ลงในตาราง cluster.Person
INSERT INTO cluster.Person
SELECT
BusinessEntityID
, Title
, FirstName
, MiddleName
, LastName
FROM AdventureWorks.Person.Person;
เมื่อทำการสืบค้นข้อมูลจากตาราง cluster.Person จะพบว่าต้นทางมีโครงสร้างตารางเป็น Clustered
SELECT * FROM cluster.Person;
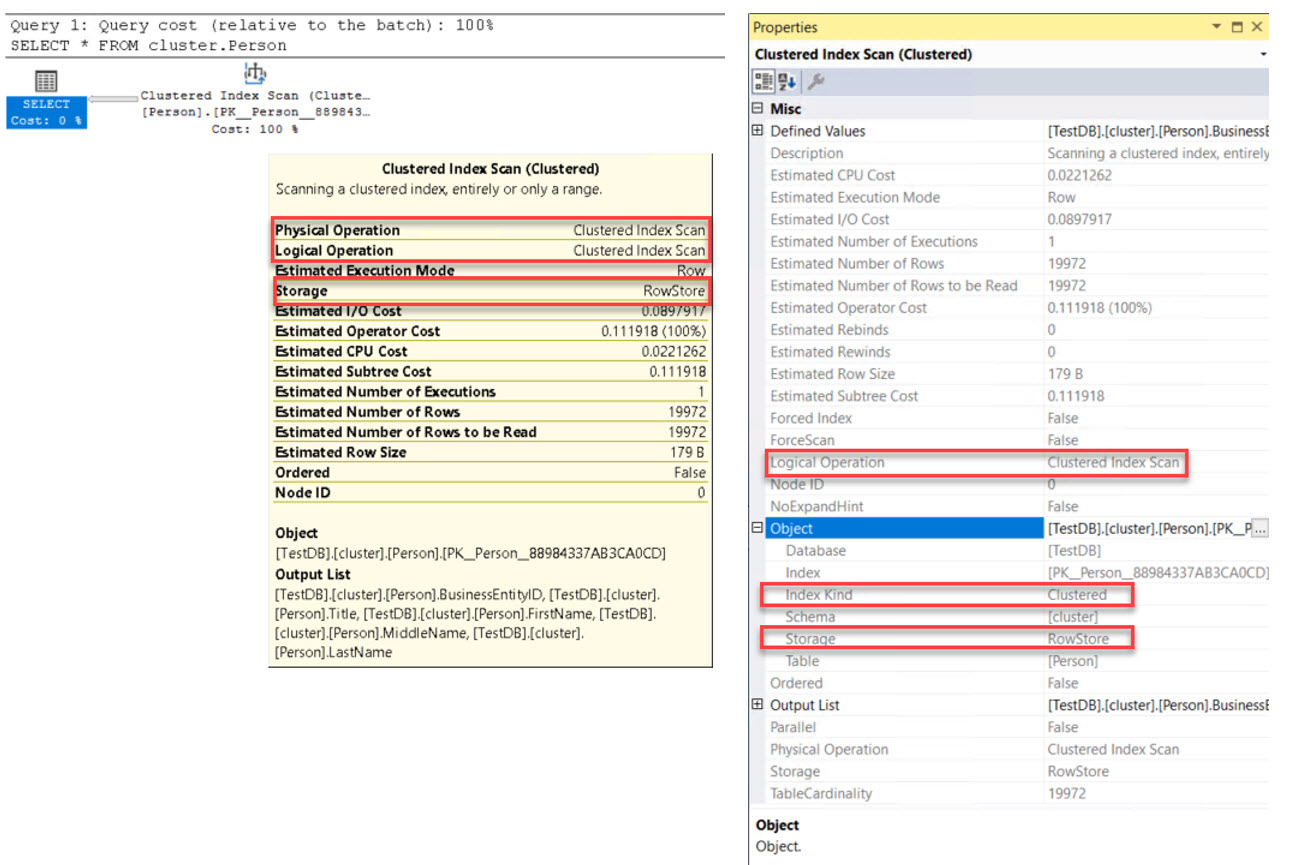
ตัวดำเนินการที่ทำให้รู้ว่าโครงสร้างตารางเป็น Clustered คือ Clustered Index Scan
และหากเข้าไปดูรายละเดียดของตัวดำเนินการโดยนำเมาส์ไปลอยเหนือตัวดำเนินการจะพบว่ามีแหล่งจัดเก็บเป็น Rowstore
หากผู้อ่านต้องการรายละเอียดที่มากขึ้นสามารถคลิกขวาที่ตัวดำเนินการ Clustered Index Scan แล้วเลือก Properties จะพบว่าชนิดของ Index เป็น Clustered
โครงสร้างตารางแบบ Column-Based Clustered
เป็นโครงสร้างตารางแบบ Column-Based เรามักเรียกว่า Clustered Columnstore Index
ซึ่งเป็นโครงสร้างตารางแบบ Column-Based ที่ผสมความเป็น Index อยู่ในตัวเอง
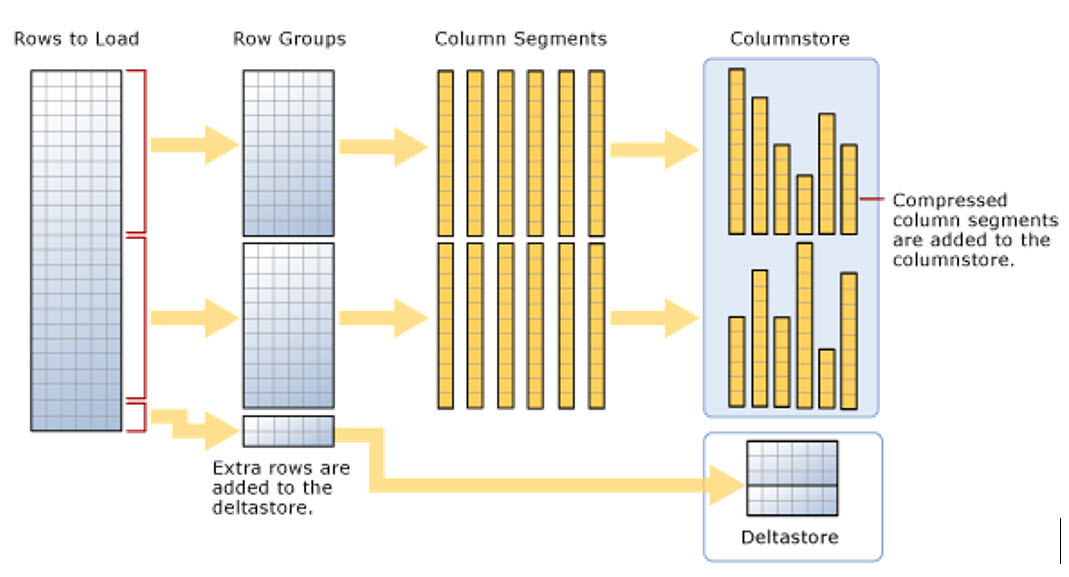
(รูปภาพจาก Microsoft)
โดยจะแยกทุกคอลัมน์ของตารางแต่ละคอลัมน์ออกมา และ บีบอัดพร้อมจัด Index ลงชุด Pages ของใครของมัน
เหมาะกับตารางที่มีความซ้ำซ้อนของข้อมูลสูง เช่น Fact Table ใน Datawarehouse เป็นต้น
ผู้เขียนจะทดสอบสร้างตารางที่มีโครงสร้างแบบ Column-Based Clustered
โดยดึงข้อมูลจากฐานข้อมูล AdventureworksDW ซึ่งเป็นฐานข้อมูลแบบ Datawarehouse
ผู้อ่านสามารถดาวน์โหลดได้จากลิ้งก์ที่ให้ไว้ก่อนหน้า แล้วนำมา Restore ได้เลย
จากนั้นทำการสร้างตาราง CCL.FactInternetSales ด้วยคำสั่ง SELECT-INTO
แล้วเปลี่ยนโครงสร้างตารางจาก HEAP ไปเป็น Column-Based Clustered
ด้วยคำสั่ง CREATE CLUSTERED COLUMNSTORE INDEX ดังแสดง
USE TestDB;
GO
CREATE SCHEMA CCL;
GO
SELECT
*
INTO CCL.FactInternetSales
FROM AdventureWorksDW.dbo.FactInternetSales
GO
CREATE CLUSTERED COLUMNSTORE INDEX CCL_IDX_FactInternetSales
ON CCL.FactInternetSales;
GO
เมื่อทำการสืบค้นข้อมูลจากตาราง CCL.FactInternetSales จะพบว่าต้นทางมีโครงสร้างตารางเป็น Column-Based Clustered
SELECT * FROM CCL.FactInternetSales;
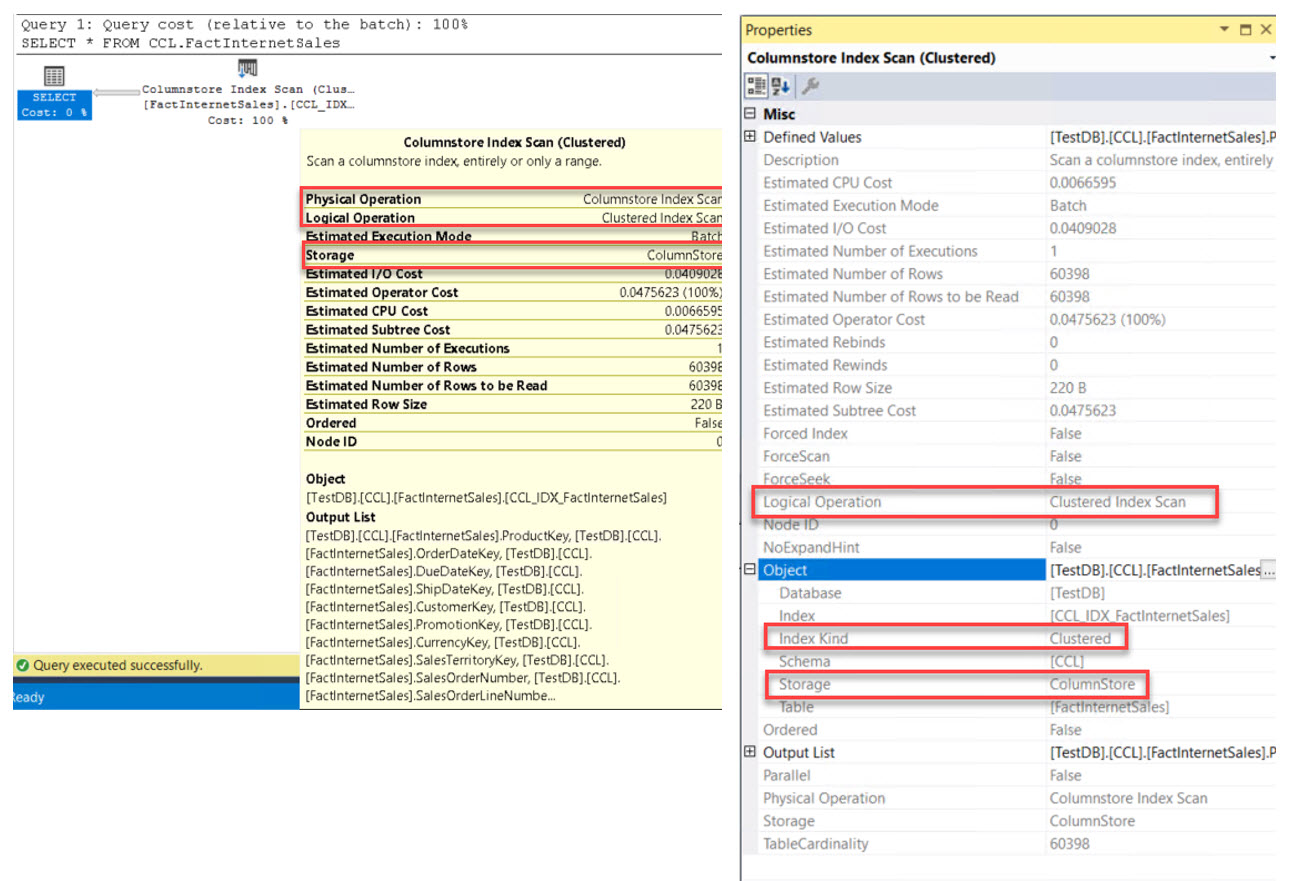
ตัวดำเนินการที่ทำให้รู้ว่าโครงสร้างตารางเป็น Column-Based Clustered คือ Columnstore Index Scan (Clustered)
และหากเข้าไปดูรายละเดียดของตัวดำเนินการโดยนำเมาส์ไปลอยเหนือตัวดำเนินการจะพบว่ามีแหล่งจัดเก็บเป็น Columnstore
หากผู้อ่านต้องการรายละเอียดที่มากขึ้นสามารถคลิกขวาที่ตัวดำเนินการ Columnstore Index Scan (Clustered)
แล้วเลือก Properties จะพบว่าชนิดของ Index เป็น Clustered
ชนิดของ Index ที่จำเป็นต่อการอ่าน Execution Plan
ผู้เขียนขอเรียก Non-Clustered Index ไม่ว่าจะเป็น Non-Clustered Index แบบ Row-Based หรือ Non-Clustered Columnstore Index แบบ Column-Based ว่า Index เฉย ๆ
เพราะดูจากการที่ถูกสร้างและบันทึกลง Pages แยกออกไปจากโครงสร้างตาราง
โดยทั้งสองแบบสามารถสร้างอยู่บนโครงสร้างตารางแบบใดก็ตามที่กล่าวก่อนหน้าได้ทั้งสิ้น
Non-Clustered Index แบบ Row-Based อยู่บนโครงสร้างตารางแบบ HEAP
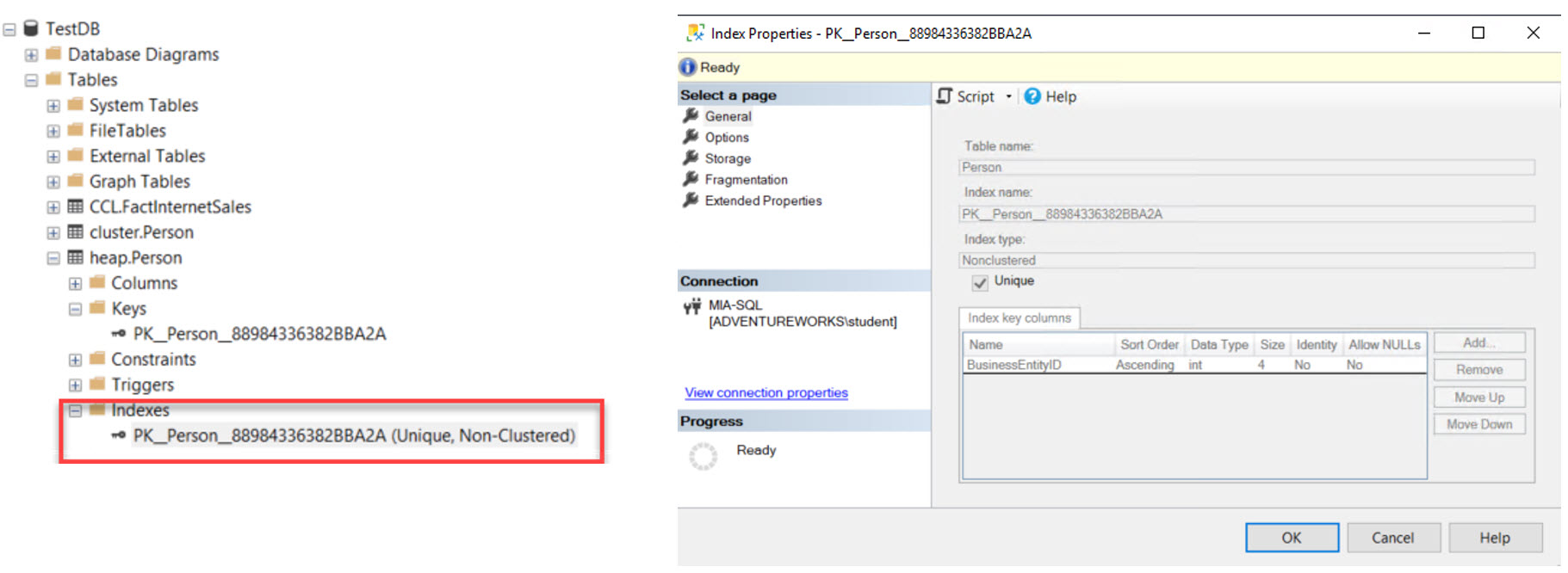
ทำให้เราได้ Non-Clustered Index มาหนึ่งตัวโดยนำคอลัมน์ที่กำหนดเป็น Primary Key มาสร้าง Non-Clustered Index ในที่นี้คือ BusinessEntityID
เมื่อทำการสืบค้นข้อมูลจากตาราง heap.Person โดยกรอง BusinessEntityID ผ่านประโยค WHERE
ะพบตัวดำเนินการ Index Seek (NonClustered) ดังแสดง
SELECT * FROM heap.Person
WHERE BusinessEntityID=16178;

โดยการประมวลผลจะเริ่มจากการค้นหาใน Non-Clustered Index ก่อนด้วย จนพบBusinessEntityID=16178
จากนั้นจะพบการระบุตำแหน่งแถวข้อมูลอยู่ใน Leaf Level ของ Non-Clustered Index
(กรณีโครงสร้างตารางเป็น HEAP จะใช้ FileGroupID+FileID+PageID+RowID)
นำไปดึงข้อมูลคอลัมน์อื่น ๆ ผ่านตัวดำเนินการ RID Lookup อีกต่อหนึ่ง
Non-Clustered Index แบบ Row-Based อยู่บนโครงสร้างตารางแบบ Row-Based Clustered
ต้องสร้าง Non-Clustered Index บนตาราง cluster.Person เพิ่มเติมดังแสดง
CREATE NONCLUSTERED INDEX NIDX_Person_LastName
ON cluster.Person
(
LastName ASC
)
GO
เมื่อทำการสืบค้นข้อมูลจากตาราง cluster.Person โดยกรอง LastName ผ่านประโยค WHERE จะพบตัวดำเนินการ Index Seek (NonClustered) ดังแสดง
SELECT * FROM cluster.Person
WHERE LastName='Zukowski';
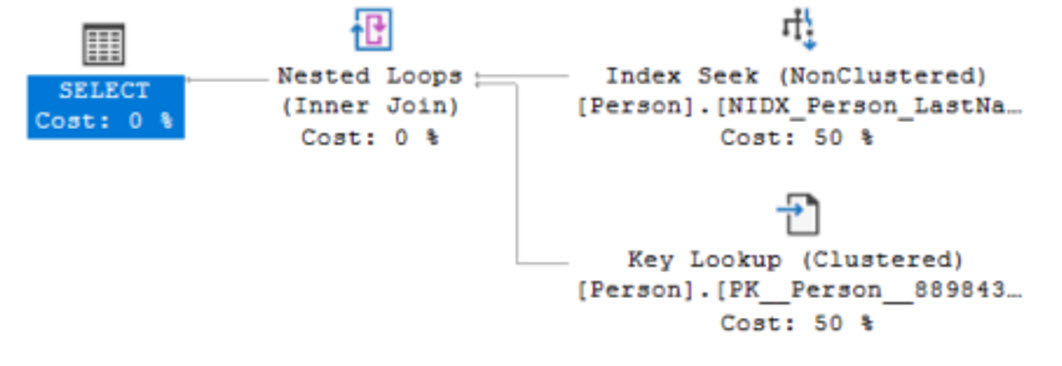
โดยการประมวลผลจะเริ่มจากการค้นหาใน Non-Clustered Index ที่สร้างขึ้นก่อนด้วย จนพบ LastName='Zukowski'
จากนั้นจะพบการระบุตำแหน่งแถวข้อมูลอยู่ใน Leaf Level ของ Non-Clustered Index
(กรณีโครงสร้างตารางเป็น Clustered จะใช้ Clustered Key)
นำไปดึงข้อมูลคอลัมน์อื่น ๆ ผ่านตัวดำเนินการ Key Lookup อีกต่อหนึ่ง
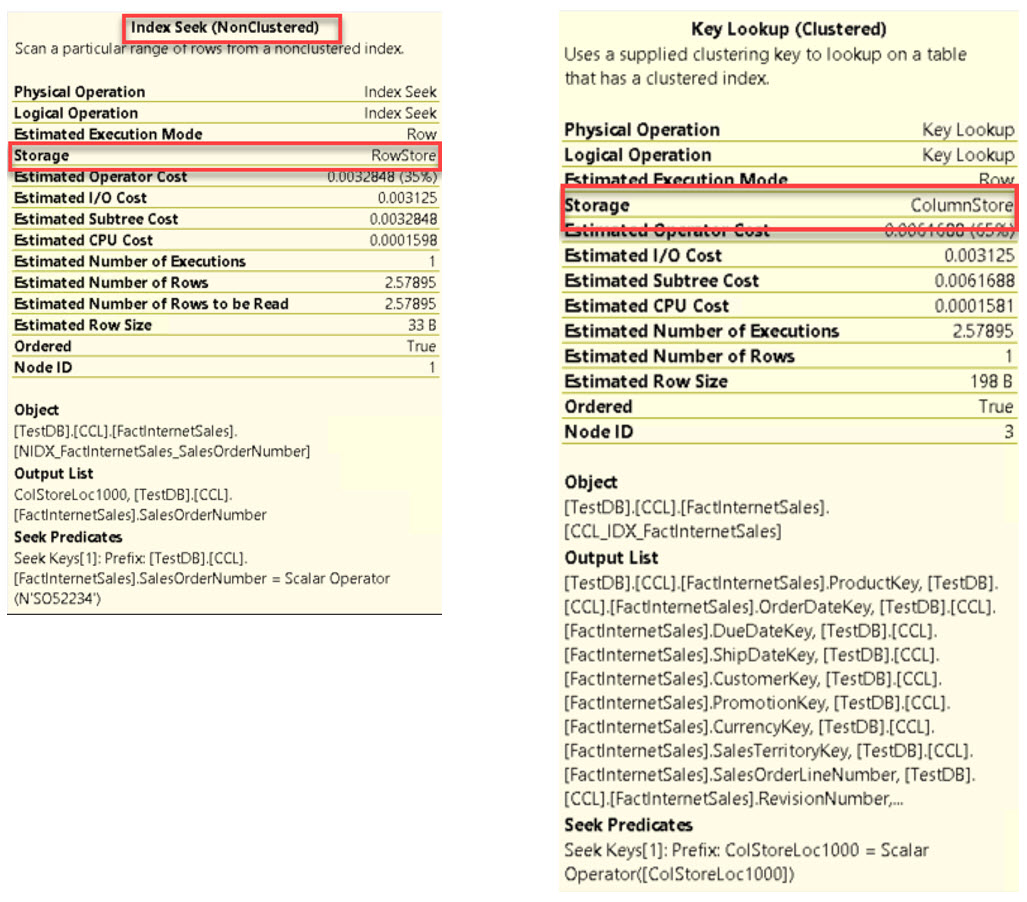
Non-Clustered Index แบบ Row-Based อยู่บนโครงสร้างตารางแบบ Column-Based Clustered
ต้องสร้าง Non-Clustered Index บนตาราง CCL.FactInternetSales เพิ่มเติมดังแสดง
CREATE NONCLUSTERED INDEX NIDX_FactInternetSales_SalesOrderNumber
ON CCL.FactInternetSales
(
SalesOrderNumber ASC
)
GO
เมื่อทำการสืบค้นข้อมูลจากตาราง CCL.FactInternetSales โดยกรอง SalesOrderNumber ผ่านประโยค WHERE จะพบตัวดำเนินการ Index Seek (NonClustered) ดังแสดง
SELECT * FROM CCL.FactInternetSales
WHERE SalesOrderNumber='SO52234';

โดยการประมวลผลจะเริ่มจากการค้นหาใน Non-Clustered Index ที่สร้างขึ้นก่อนด้วยจนพบ SalesOrderNumber='SO52234'
จากนั้นจะพบการระบุตำแหน่งแถวข้อมูลอยู่ใน Leaf Level ของ Non-Clustered Index นำไปดึงข้อมูลคอลัมน์อื่น ๆ ผ่านตัวดำเนินการ Key Lookup จากตารางที่มีโครงสร้างแบบ Column-Based Clustered อีกต่อหนึ่ง
รายละเอียดของตัวดำเนินการทั้งสองแสดงให้เห็นโครงสร้างของ Non-Clustered Index เป็นแบบ Rowstore
และโครงสร้างตารางเป็นแบบ Columnstore ดังแสดง
บทสรุป
ผู้อ่านของพอเห็นภาพกว้าง ๆ ของตัวดำเนินการ Scan และ Seek รวมทั้งโครงสร้างตารางแต่ละแบบจากตัวอย่างที่ยกมา
กรณี Non-Clustered Columnstore Index (Column-Based) บนโครงสร้างตารางแบบ HEAP, Row-Based Clustered และ Column-Based Clustered
ผู้อ่านสามารถทดลองได้ด้วยตนเอง แต่การจะเกิด Index Seek หรือไม่กลไก Query Optimization จะตัดสินใจเอง
หาก Selectivity ต่ำ บางครั้งการ Scan Table อาจคุ้มค่ากว่า